Making Electron apps feel native on Mac. Segnalibro per una lista di trucchi per rendere un'app Electron il più vicina possibile al feeling nativo.
#dev
Stop Using Conventional Commits. Ah, finalmente ho trovato il mio club. I conventional commit sono inutili nella maggior parte dei casi.
Agentic AI is a fascinating mirror. It can code as well as the user who drives it. If that user is a junior engineer, now you have a faster junior engineer. If the user is a staff engineer, now you have a faster staff engineer.
What agentic AI doesn’t do is magically convert a junior engineer into a staff engineer, because the user driving it still needs enough experience to know what a good solution looks like.
A staff engineer in the US at a large company a The Pragmatic Engineer.
It used to be if you found a GitHub repository with a hundred commits and a good readme and automated tests and stuff, you could be pretty sure that the person writing that had put a lot of care and attention into that project.
And now I can knock out a git repository with a hundred commits and a beautiful readme and comprehensive tests of every line of code in half an hour! It looks identical to those projects that have had a great deal of care and attention. Maybe it is as good as them. I don’t know. I can’t tell from looking at it. Even for my own projects, I can’t tell.
Simon Willison in Vibe coding and agentic engineering are getting closer than I’d like.
Idempotency Is Easy Until the Second Request Is Different. Deep dive nell'implementazione di idempotency nelle API HTTP.
Leggo cose buone su RWX, nuova piattaforma di CI/CD pensata per velocizzare i processi nell'era dell'AI engineering, con parallelizzazione automatica, esecuzione delle pipeline prima del commit e altre ottimizzazioni.
Imagine if this is as good as AI gets. If this is where it stops, you'd still have models that can almost code a web browser, almost code a compiler—and can even present a pretty cool demo if allowed to take a few shortcuts. You'd still get models that can kinda-sorta simulate worlds and write kinda-sorta engaging stories. You'd still get self-driving cars that almost work, except when they don't. You get AI that can make you like 90% of a thing!
90% is a lot. Will you care about the last 10%?
I'm terrified that you won't.
I'm terrified of the good enough to ship—and I'm terrified of nobody else caring. I'm less afraid of AI agents writing apps that they will never experience than I am of the AI herders who won't care enough to actually learn what they ship. And I sure as hell am afraid of the people who will experience the slop and will be fine with it.
[...]
I'm terrified that our craft will die, and nobody will even care to mourn it.
Dima Konev, software engineer, in (AI) Slop Terrifies Me.
Tokenmaxxing
It feels to me that a good part of the industry is using token count numbers similarly to how the lines-of-code-produced metric was used years ago. There was a time when the number of lines written daily or monthly was an important metric in programmer productivity, until it became clear that it’s a terrible thing to focus on. A lines-of-code metric can easily be gamed by writing boilerplate or throwaway code. Also, the best developers are not necessarily those who write the most code; they’re the ones who solve hard problems for the business quickly and reliably with – or without – code!
Similarly, the number of tokens a dev generates can easily be gamed, and if this metric is measured then devs will indeed game it. But doing so generates a massive accompanying AI bill!
Gergely Orosz in The Pulse: ‘Tokenmaxxing’ as a weird new trend.
I tre tipi di software engineer secondo The Pragmatic Engineer:
Builders: those who care about quality, good architecture, following good coding practices, and who talk about the craft of software engineering, etc.
Shippers: those who primarily focus on outcomes for a product, features, testing, and experimenting with users. A fair number of leaders, managers, and engineers who were more hands-off with coding before AI tools are in this category, as are product engineers.
Coasters: engineers who are not considered particularly good or great engineers, but they get the work done. They often do this without much taste or concern for quality, and seem to be mostly coasting along and doing what they’re told.
Con l'AI, queste categorie restano ma con diversi livelli di entusiasmo e pro/contro. Il resto nell'articolo.
DNSimple spiega come gestiscono le repository GitHub con Terraform. Quando iniziano a diventare centinaia, gestirle manualmente genera inconsistenze:
- Repositories had different settings, even when they should have been identical
- Labels for issue triage varied from repository to repository, making cross-project tracking difficult
- Some repositories had issue templates, while others didn't
- Permission management was manual and error-prone
- Security features like vulnerability alerts weren't consistently enabled
- Pull request templates were copy-pasted (when they existed at all)
Dopo un tentativo con Repocop, per automatizzare il setup, hanno deciso di usare Terraform con aggiornamento delle configurazioni tramite Pull Request e Terraform Cloud.
2FA for developers
Ho aggiunto il supporto all'autenticazione a due fattori su DMARCwise e ho fatto fatica a trovare informazioni su best practice attorno alla 2FA con OTP, per cui segno quello che ho scoperto qui.
Intanto, l'algoritmo si chiama Time-based One-Time Password (TOTP) e permette di generare un codice di N cifre ogni T secondi partendo da un secret. Non tutte le app "authenticator" supportano tutte le configurazioni, per cui la più comune è:
- Codici di 6 cifre.
- Intervallo di tempo T di 30 secondi.
- Algoritmo HMAC-SHA1.
Il secret nella maggior parte dei casi è di 20 byte (160 bit) e viene codificato in Base32 (es. CVEBO7GKWLFDRBJRPPTOZ7I6VEPDIGIT). Va generato diverso per ogni utente.
Per la verifica del TOTP la RFC consiglia di usare una tolleranza (drift window) di +/- un intervallo di tempo T (quindi vale sia il codice precedente che quello successivo).
Il secret andrebbe cifrato prima di essere inserito nel database. Nel mio caso ho scelto AES-256 GCM. Nel db vanno quindi salvati il secret cifrato (Base64) più il nonce e il tag AES.
Per la validazione dei codici ho usato la libreria Otp.NET per .NET/C#. Per AES ho usato l'implementazione nativa di .NET.
Per la configurazione iniziale del secondo fattore, all'utente vanno forniti il secret e i vari parametri menzionati sopra (o anche no, dato che quelli indicati qui sopra sono di solito il default), oppure un QR code che contiene un URI con questo formato (inizialmente definito da Google ma ora standard de facto):
otpauth://totp/{label}:{accountName}?secret={secret}&issuer={issuer}";
I parametri vanno URL encoded. La prima etichetta viene mostrata nella UI dell'applicazione authenticator di turno (Google Authenticator, Ente Auth, ecc.) assieme al nome dell'account, mentre l'issuer dovrebbe essere a uso interno.
Il codice QR lo genero server-side in SVG con ZXing.QrCode e lo ritorno nella risposta JSON delle API. Probabilmente si può fare anche client-side, ma avevo già generato QR in C# in un altro progetto per cui ho riciclato il codice.
Per confermare l'abilitazione della 2FA l'utente deve inserire un primo codice TOTP generato dall'app authenticator. C'è la possibilità che l'utente abbandoni il processo a metà, per cui ci vuole un cleanup delle configurazioni che non sono ancora state abilitate dopo 24/48 ore.
Andrebbero poi generati e forniti dei codici di backup/recupero. Nel mio caso sono 10 codici di 8 caratteri presi dall'alfabeto ABCDEFGHJKLMNPQRSTUVWXYZ23456789 (es. BVEZ-MMWP). Sono hashati con Argon2id, come le password, e salvati in una tabella del db. Di conseguenza nel momento della verifica del backup code bisogna verificarli tutti uno a uno per trovare se c'è un match, e poi segnare il codice individuato come già usato.
Come si implementa la verifica del secondo fattore in fase di login? Il login restituisce un token di tipo TwoFactorPending e il frontend fa redirect alla pagina di verifica. Questo token temporaneo permette di usare solo l'endpoint di verifica 2FA. Se il codice inserito dall'utente è corretto viene invalidato il token temporaneo (che ha comunque scadenza breve, es. 5 minuti) e ne viene creato uno nuovo "standard".
La disattivazione del secondo fattore deve richiedere la password dell'utente, mentre la rigenerazione dei codici di backup deve richiedere un codice TOTP valido (per verificare che l'utente sia effettivamente ancora in possesso del secondo fattore).
Bonus: il 95% del codice è stato scritto da Claude Code e dall'inizio alla fine ci abbiamo impiegato circa 3 giorni (progettazione, implementazione di 6 endpoint backend, integration test e tutta la UI con SvelteKit).
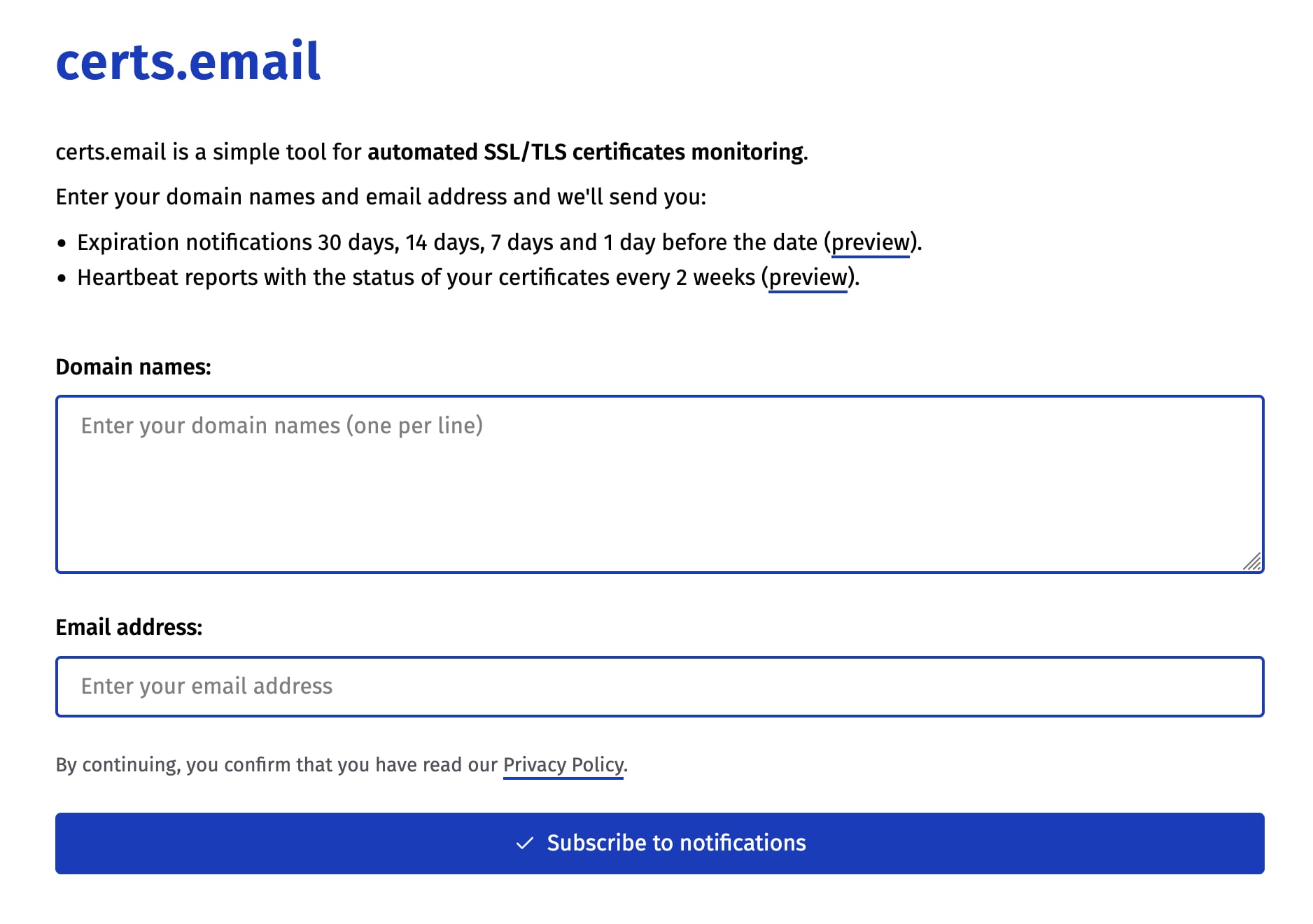
certs.email
Ho pubblicato certs.email: un mini-servizio per essere notificati all'avvicinamento della scadenza dei certificati SSL/TLS dei propri domini.
È gratis e open source e in realtà mi serve prevalentemente per avere un dominio in più che invia email, per poter testare meglio DMARCwise.
Segmentation fault in una build TypeScript mi giunge nuova:
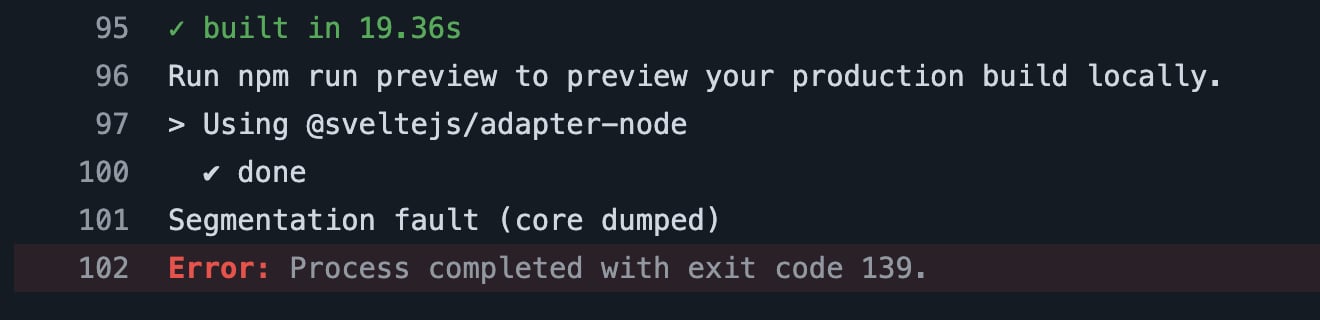
EDIT: era colpa di una libreria con binding Rust, il che ha ancora meno senso in realtà.
Nuovo mini progetto work in progress:
Un sito ben fatto, Logging Sucks, per spiegare due concetti di logging nelle applicazioni:
- Structured logging, cioè spezzare il messaggio testuale nelle sue componenti in modo che siano filtrabili (ogni log line è un oggetto JSON, in pratica).
- Wide events, cioè avere una singola log line per ciascun evento nel senso più ampio possibile. Ad esempio una richiesta HTTP produce un log che contiene tutte le info di contesto su ciò che è successo durante l'elaborazione, al posto di avere le informazioni sparse tra più righe di log.
Molto d'accordo sul primo (anche se preferisco una forma ibrida con messaggio formattato + variabili scorporate), meno sul secondo. Righe di log separate con un id di correlazione lo troverei più comodo (a meno di logging su scale enormi che finora non mi sono capitate).
Postmortem di Railway, la creazione di un indice PostgreSQL ha tirato giù tutto:
A routine change to this Postgres database introduced a new column with an index to a table containing approximately 1 billion records. This table is critical in our backend API’s infrastructure, used by nearly all API operations.
The index creation did not use Postgres’ CONCURRENTLY option, causing an exclusive lock on the entire table. During the lock period, all queries against the database were queued behind the index operation. [...] Manual intervention attempts to terminate the index creation failed.
Le misure:
We’re going to introduce several changes to prevent errors of this class from happening again:
- In CI, we will enforce CONCURRENTLY usage for all index creation operations, blocking non-compliant pull requests before merge.
- PgBouncer connection pool limits will be adjusted to prevent overwhelming the underlying Postgres instance's capacity.
- Database user connection limits will be configured to guarantee administrative access during incidents, ensuring maintenance operations remain possible under all conditions.
Mistral vibe
Oui oui baguette 😂
How we deploy the largest GitLab instance 12 times daily. La strategia di deployment di GitLab, interessante per la scala, per la progressività con canary e la strategia di migrazione del db.
Ottimizzazioni di un'altra era nell'app Facebook:
In 2012 we took this wild ride at mobile infra at Facebook when trying to reduce the several-seconds long load time for “Newsfeed”. A few people worked on different approaches. Something we quickly realized was that setting up a connection with TCP and TLS was incredibly slow on mobile networks at the time. The fix was to have just one, keep it alive and multiplex. Shaved a whole second off. But it was still slow. Several people were convince that us sending JSON was the problem, so two different teams started to work on compact binary encoding. After a lot of experimentation what actually worked out best was to send JSON with ordered fields and a compile-time generated parser. Turns out both our iOS and Android app would do something silly like: 1) read all JSON data from server into a buffer, 2) decode that buffer with a generic JSON decoder into lists & dicts, 3) traverse those structures and build the final struct/class tree. Oh and another neat thing we eventually did—when the network connection needed to be setup—was to send an optimistic UDP packet to the server saying “get started fetching data for the following query”; once the real connection was established, TLS handshake completed and user session authenticated, the response was already ready to be sent back.
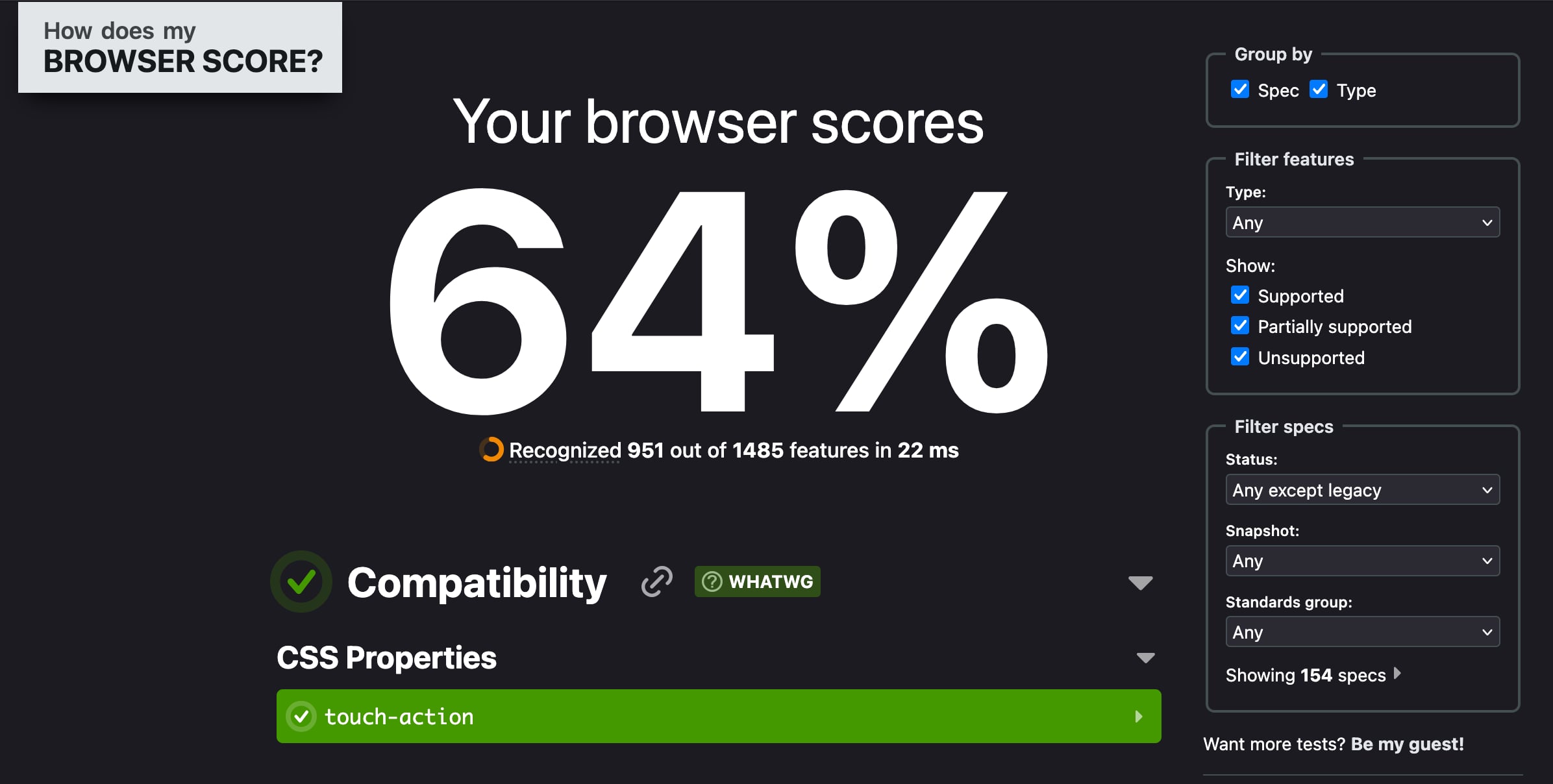
Browser Score permette di verificare se il proprio browser supporta determinate feature di CSS.
Pagina 1 di 3 Successiva →
Archivio
- 2026
- giugno (24)
- maggio (29)
- aprile (67)
- marzo (55)
- febbraio (40)
- gennaio (54)
- 2025
- dicembre (79)
- novembre (63)
- ottobre (102)
- settembre (22)
Tag
- #ai (113)
- #cloud (55)
- #dev (48)
- #italia (46)
- #business (26)
- #openai (25)
- #digitalizzazione (25)
- #internet (22)
- #security (21)
- #cdn (21)
- #mondo (21)
- #database (19)
- #social (18)
- #reti (18)
- #cloudflare (17)
- #aws (16)
- #google (15)
- #informazione (15)
- #video (15)
- #claude (15)
- #browser (14)
- #mobilità (13)
- #storage (13)
- #macos (12)
- #anthropic (11)
- #domini (11)
- #meta (10)
- #scrivere (10)
- #github (9)
- #dns (8)
- #web-dev (8)
- #open-source (7)
- #design (7)
- #pagopa (7)
- #telegram (7)
- #http (7)
- #git (6)
- #codex (6)
- #dataviz (6)
- #tlc (6)
- #amazon (6)
- #email (5)
- #hetzner (5)
- #bending-spoons (5)
- #libri (5)
- #ovh (5)
- #microsoft (5)
- #antipirateria (4)
- #agenziadelleentrate (4)
- #innovazione (4)
- #privacy (4)
- #streaming (4)
- #waymo (3)
- #mistral (3)
- #kubernetes (3)
- #whatsapp (3)
- #energia (3)
- #cie (3)
- #ipv6 (3)
- #apple (3)
- #opendata (3)
- #colori (2)
- #eu (2)
- #windows (2)
- #datacenter (2)
- #android (2)
- #javascript (2)
- #trenitalia (2)
- #broadcasting (1)
- #markdown (1)
- #blog (1)
- #postgres (1)
- #dotnet (1)
- #revolut (1)
- #rai (1)
- #akamai (1)
- #legal (1)
- #redis (1)
- #tailscale (1)