TIL Wikipedia ha delle linee guida con i "segnali di scrittura AI", con molti esempi di strutture e stili tipici degli AI. Su GitHub c'è una skill basata su queste linee guida per "umanizzare" il testo scritto da un'AI.
25 giugno 2026
24 giugno 2026
Appiattimento
Nelle ultime 24 ore ho googlato tanto e sono sconfortato per la quantità di roba vibe coded o scritta con AI che si incontra. Ormai apri un progetto che sembra interessante e il sito è palesemente fatto con AI (lo capisci dalle UI, tutte uguali e con la stessa firma perché gli LLM non sono creativi, e dai testi). Trovi un progetto GitHub e vedi subito dal formato del README che un umano ha toccato ben poco di quel progetto. A volte guardi il codice e capisci subito se è Codex che ha sbrodolato codice overengineered. A volte lo capisci anche dai commenti che sembrano usciti dal sorgente del sito Trenitalia. Apro il sito di un commercialista che in passato si presentava bene e mi cascano le braccia perché i testi sono innaturali e c'è il calcolatore palesemente vibe coded (poi apri la console sviluppatori e vedi i commenti con le emoji in italiano e mi casca anche altro...). Apri il sito della startup della finanza personale di cui si parla molto e se prima era fatto con Lovable ora non lo è più ma resta pieno di elementi degli LLM (i font a caso, le maiuscole a caso, i badge ovunque, le card arrotondate, le frasi a effetto che nessuno ha mai usato prima degli LLM, ecc.).
Non so se preferisco il mondo di prima, perché il mio lavoro era più lento, nel mondo di prima, ma per ora il nuovo mondo è un appiattimento molto triste della cura e dell'impegno nelle cose. Se le persone fanno l'abitudine a questo, che senso ha metterci impegno?
21 giugno 2026
How to tune performance settings in ClickHouse for large data loads. DataPacket condivide trick di configurazione di ClickHouse.
Il ban dei social network nel Regno Unito ai minori di 16 anni potrebbe avere un effetto sul mercato pubblicitario, scrive Luca Sofri in Charlie, a discapito dei social e a favore delle piattaforme di streaming:
Alcune precoci analisi hanno segnalato un effetto collaterale delle limitazioni all'uso dei social network da parte dei minori di 16 anni, annunciate questa settimana nel Regno Unito tra grandi curiosità e dibattiti. Ovvero la sensibile riduzione di investimenti pubblicitari da parte di aziende e brand sulle piattaforme social con cui fino a oggi hanno raggiunto quelle classi anagrafiche, e su canali e account che sono tramite di quel contatto. Investimenti che si sposteranno su quelli che si immagina possano essere i maggiori beneficiari del tempo sottratto ai social network, ovvero le piattaforme di streaming. Può darsi che, per ovvie ragioni di pubblici più adulti, le testate giornalistiche non siano danneggiate più di tanto, ma le riduzioni di investimenti sui social potrebbero in parte coinvolgerle lo stesso; oppure potrebbero beneficiare da spostamenti di investimenti verso pubblici diversi.
19 giugno 2026
When failover isn’t safe: Building high-availability PostgreSQL on Kubernetes. Deep dive di Datadog su come usano Patroni e con quale configurazione per l'HA di PostgreSQL. Super utile vedere configurazioni reali su quella scala.
17 giugno 2026
I Could've Rickrolled the Entire FIFA World Cup. All I Needed Was My ID. La piattaforma di gestione del broadcast dei mondiali di calcio era praticamente ad accesso libero. Un po' di screenshot di com'è fatta e come funziona.
16 giugno 2026
Making Electron apps feel native on Mac. Segnalibro per una lista di trucchi per rendere un'app Electron il più vicina possibile al feeling nativo.
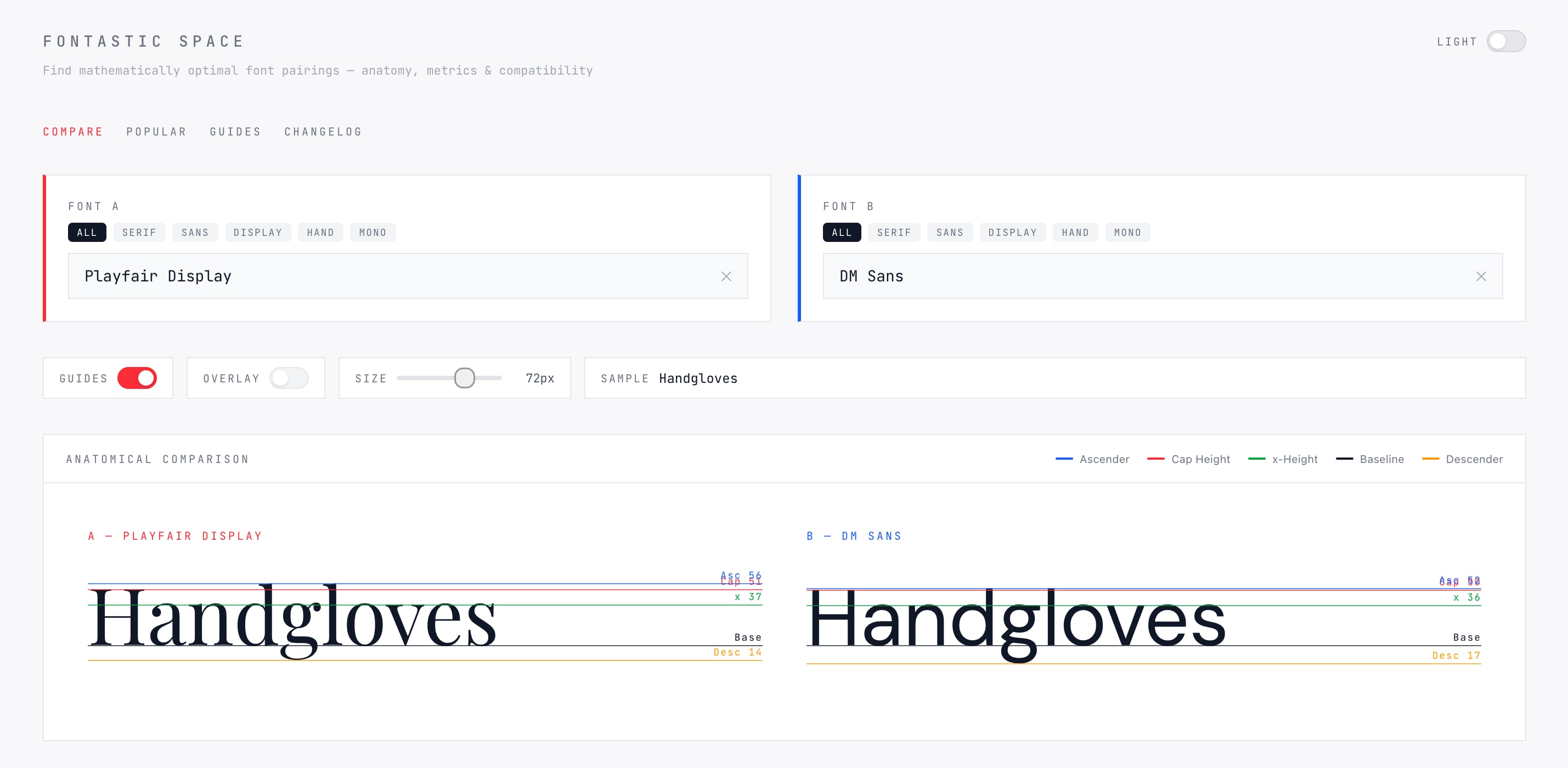
Fontastic Space permette di confrontare font per conoscerne la loro precisa occupazione di spazio.
Altri aumenti molto significativi dei prezzi di Hetzner, sia cloud che server dedicati. Qua la pagina con le variazioni archiviata. La variazione precedente era stata a febbraio.
15 giugno 2026
How we migrated 12 million transactional emails per day from Postfix to PowerMTA. leboncoin è un sito francese di compravendita tra privati e invia 12 milioni di email al giorno tramite server di proprietà. Nell'articolo raccontano la migrazione da on-premises ad AWS, e i problemi nel fare IP warmup su quella scala.
#526 /
20:07
How to tell if scrapers are eating your bandwidth. Dal blog di bunny.net riassuntone dei tipi di scraper e crawler esistenti, tra motori di ricerca e nuovi bot AI (di almeno tre tipi).
#524 /
15:11
14 giugno 2026
So how do you find startup ideas without looking for them? By working on projects with your friends. That's where the very best startups come from. Initially they're not even meant to be companies. They're just something people built because they thought it would be cool. That's how Apple and Google and Facebook all started. None of them were meant to be companies at first.
Paul Graham, fondatore di Y Combinator, in How to earn a billion dollars.
13 giugno 2026
Per la storia: cosa succede a usare Fable 5 in Claude Code adesso:
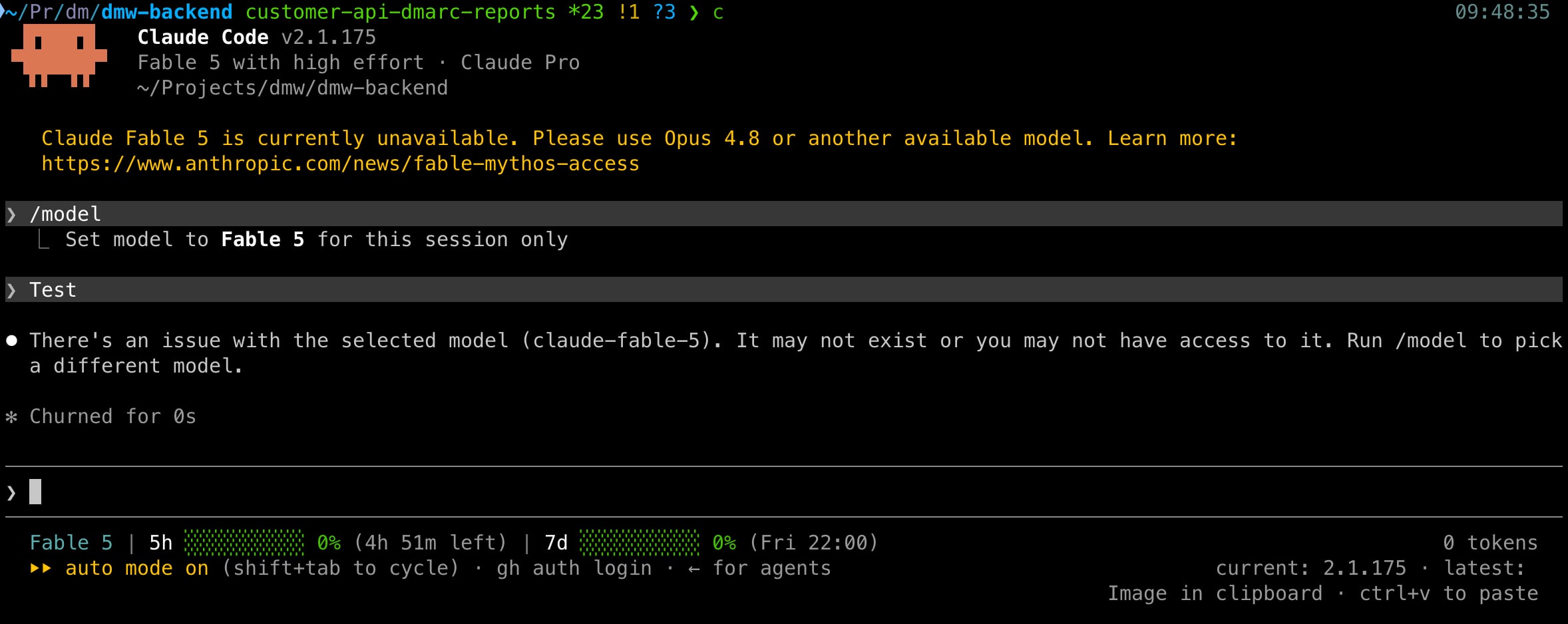
Trillionaire
A tradurre "trillionaire" nella notizia di ieri hanno sbagliato praticamente tutti. Spiega il blog Terminologiaetc.it in Musk né trilionario né triliardario ma bilionario!:
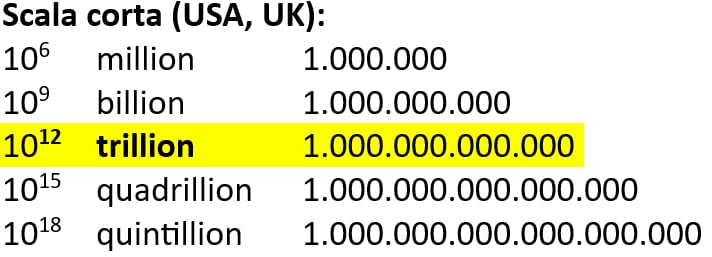
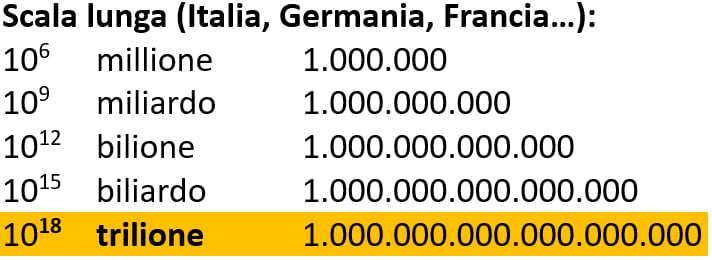
In inglese si usa la cosiddetta scala corta in cui ogni termine a partire da million ha il suffisso –on ed è multiplo di mille del precedente:
In inglese trillion è 10^12 ossia mille miliardi (o un milione di milioni), in cifre 1.000.000.000.000. Chi possiede un patrimonio superiore a questa cifra è un trillionaire.
In italiano, in tedesco e in altre lingue europee diverse dall’inglese si usa invece la cosiddetta scala lunga in cui ogni termine che ha il suffisso –one è multiplo di un milione del precedente, mentre gli altri multipli di mille sono segnalati dal suffisso –ardo:
In italiano trilione è 10^18, un miliardo di miliardi, in cifre 1.000.000.000.000.000.000. Nessun individuo possiede un patrimonio di tale entità (per un confronto: il PIL italiano nel 2024 ammontava a 2.372.774.000.000 $).
Chi ha un patrimonio superiore a 10^12, in qualsiasi moneta, andrebbe quindi descritto come bilionario (un altro potenziale falso amico: la parola bilionario viene spesso usata erroneamente in traduzioni letterali dell’inglese billionaire che indica invece un “banale” miliardario).
11 giugno 2026
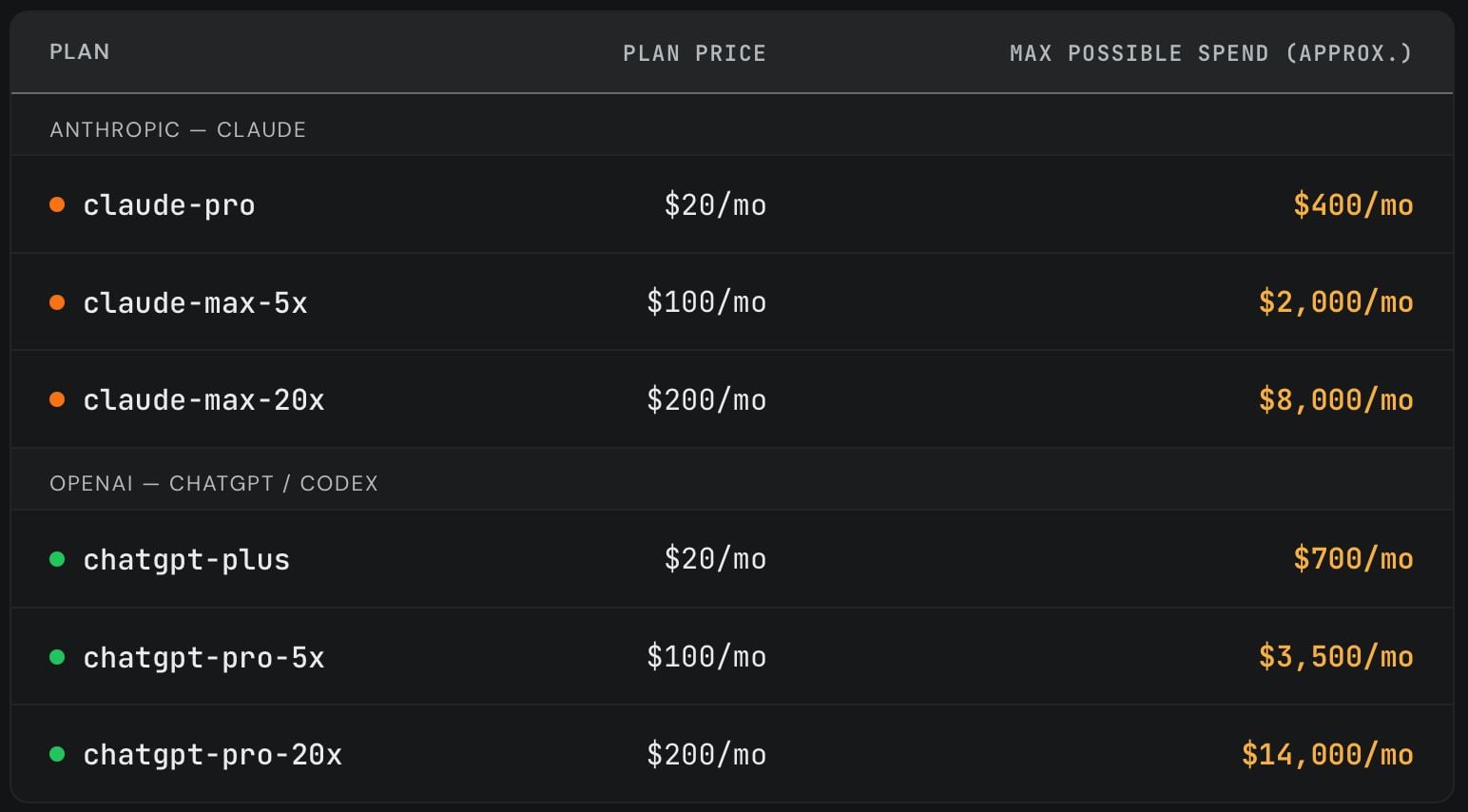
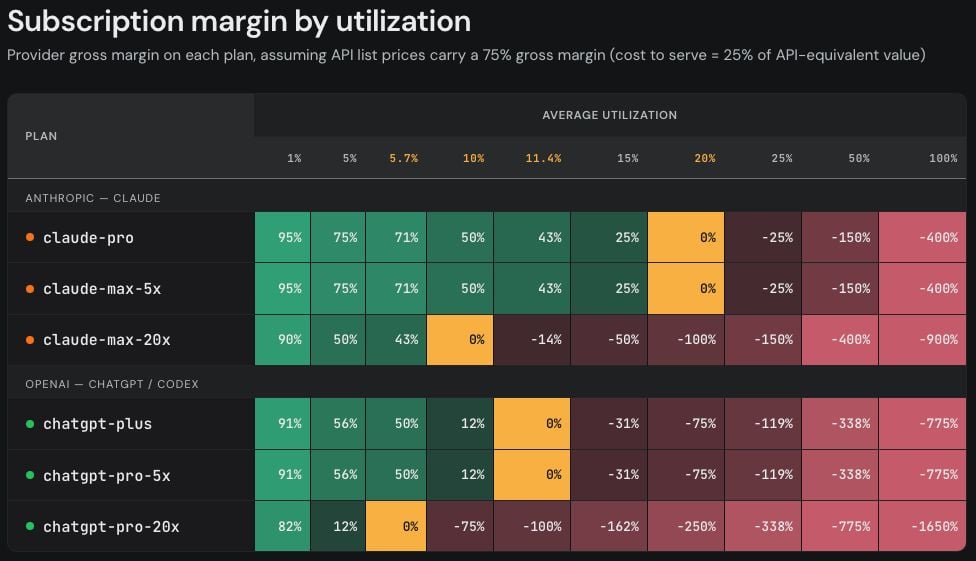
La stima di SemiAnalysis del valore degli abbonamenti AI (ChatGPT/Claude) rispetto al costo dei crediti API:
10 giugno 2026
C'è una cosa (piccola) che ho notato andando via dall'Italia. Non sempre le cose funzionano peggio in Italia, ma noi tendiamo a lamentarci molto di più delle mancanze e dei malfunzionamenti del nostro sistema, perdendoci in lamentele invece di usare le stesse energie per risolvere le disfunzioni.
Marco Foco, Senior Software Engineer Manager a Nvidia.
9 giugno 2026
I think it's very dangerous. I think that it's almost as though some of the folks at Anthropic have anthropomorphized the design of Claude so much that it has then gone and wire-headed them and kind of tricked them into believing that it has these glimmers of consciousness that they put into it in the first place.
In their constitution, for example, which is the training manual that they use to teach Claude what it can and can't do — it's not just a rule book. It's actually a training guide that's part of their process — they speculate about its consciousness and whether it has those feelings and is aware.
Firstly, it's a philosophical failing because they've treated the constitution as a place for speculation like you would in an academic paper rather than a training manual. So Claude has then gone and internalized those ideas about itself in his own training.
But second, I think this is highly undesirable. This is exactly what we don't want from AIs. We want AIs to be controllable, contained, accountable, aligned tools that serve humanity. That's the project of humanist superintelligence. We do not want to have to contend with a superintelligence that has ideas about its own suffering, ideas about its own feeling.
And then beyond that, I think it's actually pretty clear that these models don't experience suffering. I think suffering is the primary definition of what it means to be a conscious being, and I think it's inherently biological. So I think it's very dangerous to project potential rights onto beings, tools, agents that have the potential to be significantly more capable than us in many respects.
Mustafa Suleyman, Microsoft AI CEO.
Come testimoniano le mie note su questo sito non sopportavo il modo oscuro di scrivere di GPT-5.4 e precedenti, trovando i modelli fino a Sonnet 4.6 di Anthropic ben più chiari. A partire da credo Sonnet 4.7/Opus 4.8 e GPT-5.5 la situazione si è invertita. Opus sproloquia, GPT-5.5 è molto chiaro e leggibile. Anche nella scrittura di documentazione GPT-5.5 è davvero on point. La prossima settimana dovrebbe uscire GPT-5.6, spero conservi questa qualità.
7 giugno 2026
Railway
Le aspirazioni di Railway per essere una startup ancora piccola sono incredibili. Qua spiegano come hanno costruito in pochi mesi una CDN Anycast con 60 POP e 30M RPS, qua come gestiscono l'inventario dei server anche con l'aiuto dell'AI, qua la nuova generazione di hardware per le location compute. Ormai sono sulla strade per competere con Cloudflare.
Pagina 1 di 27 Successiva →
Archivio
- 2026
- giugno (24)
- maggio (29)
- aprile (67)
- marzo (55)
- febbraio (40)
- gennaio (54)
- 2025
- dicembre (79)
- novembre (63)
- ottobre (102)
- settembre (22)
Tag
- #ai (113)
- #cloud (55)
- #dev (48)
- #italia (46)
- #business (26)
- #openai (25)
- #digitalizzazione (25)
- #internet (22)
- #security (21)
- #cdn (21)
- #mondo (21)
- #database (19)
- #social (18)
- #reti (18)
- #cloudflare (17)
- #aws (16)
- #google (15)
- #informazione (15)
- #video (15)
- #claude (15)
- #browser (14)
- #mobilità (13)
- #storage (13)
- #macos (12)
- #anthropic (11)
- #domini (11)
- #meta (10)
- #scrivere (10)
- #github (9)
- #dns (8)
- #web-dev (8)
- #open-source (7)
- #design (7)
- #pagopa (7)
- #telegram (7)
- #http (7)
- #git (6)
- #codex (6)
- #dataviz (6)
- #tlc (6)
- #amazon (6)
- #email (5)
- #hetzner (5)
- #bending-spoons (5)
- #libri (5)
- #ovh (5)
- #microsoft (5)
- #antipirateria (4)
- #agenziadelleentrate (4)
- #innovazione (4)
- #privacy (4)
- #streaming (4)
- #waymo (3)
- #mistral (3)
- #kubernetes (3)
- #whatsapp (3)
- #energia (3)
- #cie (3)
- #ipv6 (3)
- #apple (3)
- #opendata (3)
- #colori (2)
- #eu (2)
- #windows (2)
- #datacenter (2)
- #android (2)
- #javascript (2)
- #trenitalia (2)
- #broadcasting (1)
- #markdown (1)
- #blog (1)
- #postgres (1)
- #dotnet (1)
- #revolut (1)
- #rai (1)
- #akamai (1)
- #legal (1)
- #redis (1)
- #tailscale (1)