La stima di SemiAnalysis del valore degli abbonamenti AI (ChatGPT/Claude) rispetto al costo dei crediti API:
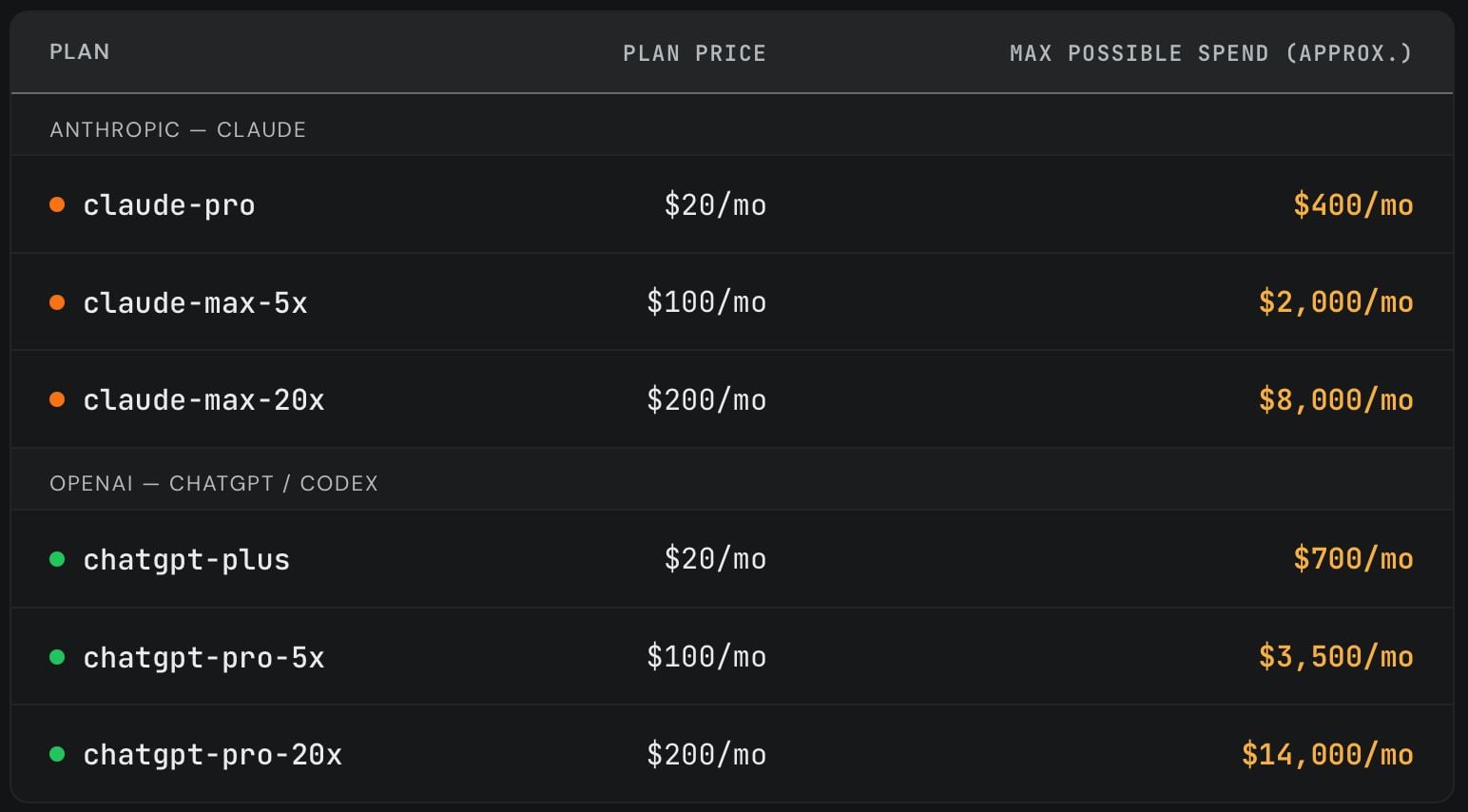
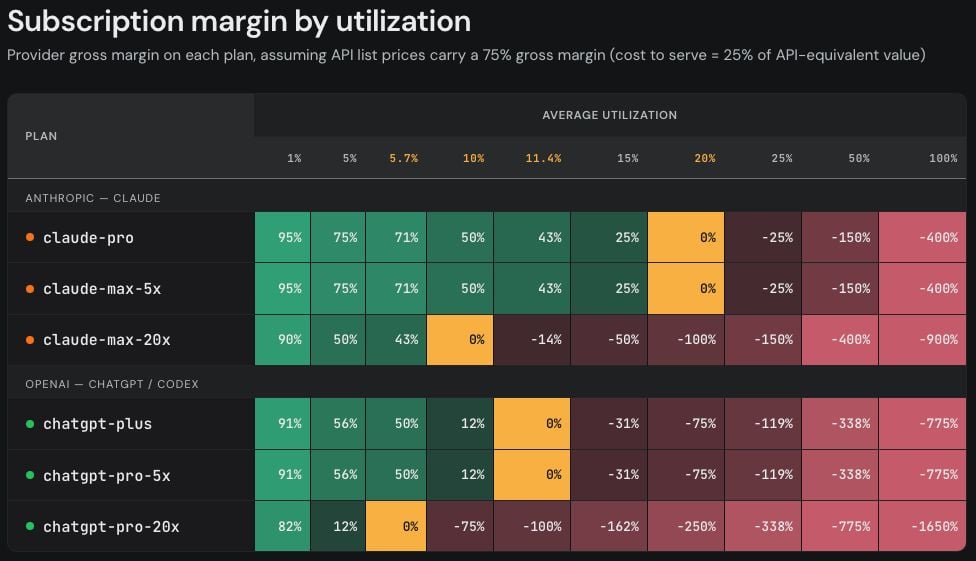
La stima di SemiAnalysis del valore degli abbonamenti AI (ChatGPT/Claude) rispetto al costo dei crediti API:
Come testimoniano le mie note su questo sito non sopportavo il modo oscuro di scrivere di GPT-5.4 e precedenti, trovando i modelli fino a Sonnet 4.6 di Anthropic ben più chiari. A partire da credo Sonnet 4.7/Opus 4.8 e GPT-5.5 la situazione si è invertita. Opus sproloquia, GPT-5.5 è molto chiaro e leggibile. Anche nella scrittura di documentazione GPT-5.5 è davvero on point. La prossima settimana dovrebbe uscire GPT-5.6, spero conservi questa qualità.
La mia esperienza media con Codex, che lo rende per me inusabile:

Un tizio ha studiato l'over-editing dei modelli linguistici e in effetti i modelli GPT sono quelli che tendono ad aggiungere più complessità.
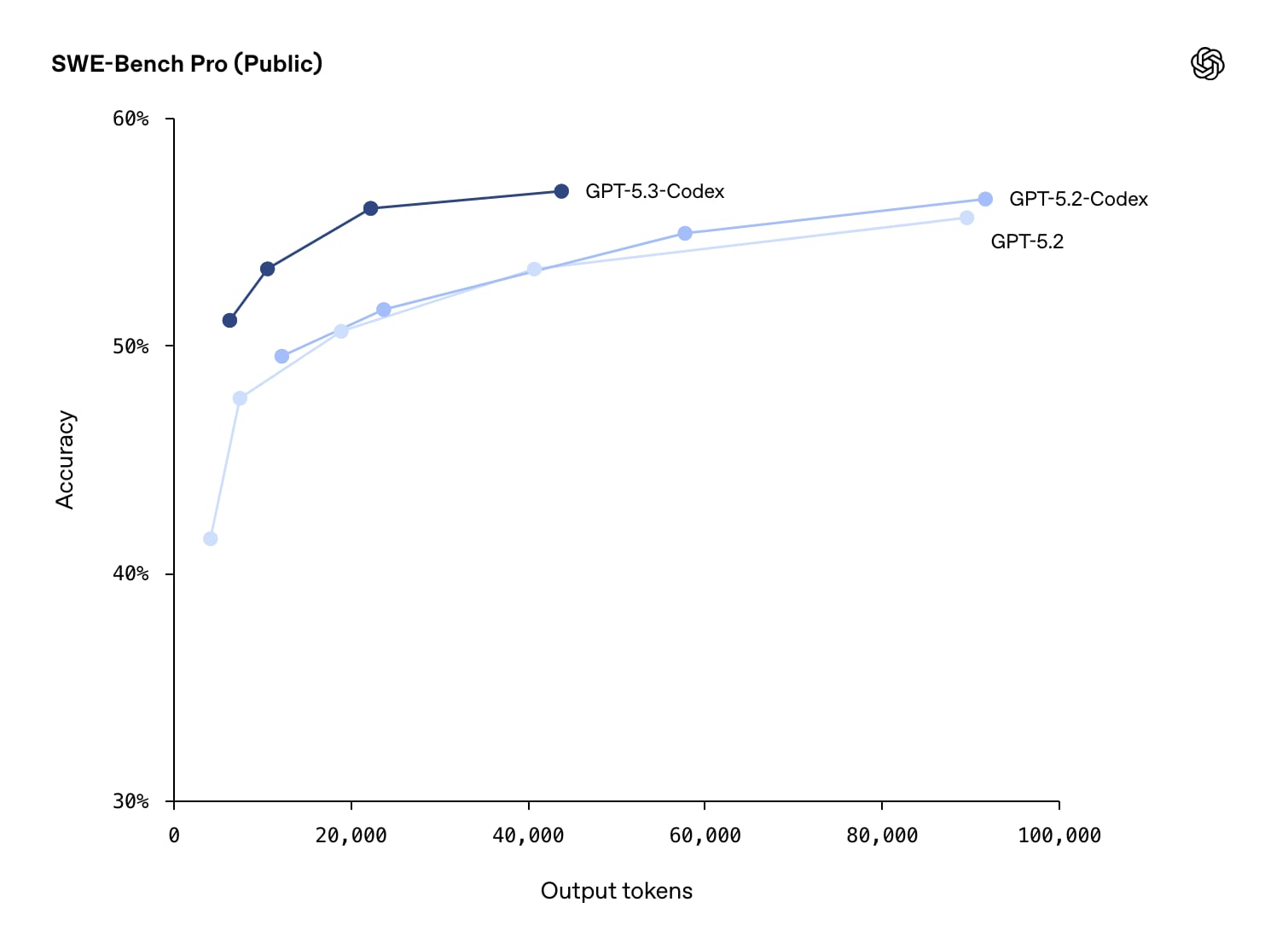
I progressi degli LLM nella programmazione sono ancora impressionanti. GPT-5.3 Codex supera la precedente versione nel benchmark SWE-Bench Pro pur usando la metà dei token di output (ragionamento incluso) e costando quindi (circa) la metà.
Il mio messaggio medio a Codex (GPT-5.2 Codex medium):

Non capisco perché a molti piaccia più di Claude Code.
A volte Codex CLI è veramente stupido:
I need to inspect each file that imports '$lib/app/responses/domains-groups', but I failed due to quoting the route path incorrectly. I haven’t modified anything yet.
E si ferma.