TIL Wikipedia ha delle linee guida con i "segnali di scrittura AI", con molti esempi di strutture e stili tipici degli AI. Su GitHub c'è una skill basata su queste linee guida per "umanizzare" il testo scritto da un'AI.
#ai
Appiattimento
Nelle ultime 24 ore ho googlato tanto e sono sconfortato per la quantità di roba vibe coded o scritta con AI che si incontra. Ormai apri un progetto che sembra interessante e il sito è palesemente fatto con AI (lo capisci dalle UI, tutte uguali e con la stessa firma perché gli LLM non sono creativi, e dai testi). Trovi un progetto GitHub e vedi subito dal formato del README che un umano ha toccato ben poco di quel progetto. A volte guardi il codice e capisci subito se è Codex che ha sbrodolato codice overengineered. A volte lo capisci anche dai commenti che sembrano usciti dal sorgente del sito Trenitalia. Apro il sito di un commercialista che in passato si presentava bene e mi cascano le braccia perché i testi sono innaturali e c'è il calcolatore palesemente vibe coded (poi apri la console sviluppatori e vedi i commenti con le emoji in italiano e mi casca anche altro...). Apri il sito della startup della finanza personale di cui si parla molto e se prima era fatto con Lovable ora non lo è più ma resta pieno di elementi degli LLM (i font a caso, le maiuscole a caso, i badge ovunque, le card arrotondate, le frasi a effetto che nessuno ha mai usato prima degli LLM, ecc.).
Non so se preferisco il mondo di prima, perché il mio lavoro era più lento, nel mondo di prima, ma per ora il nuovo mondo è un appiattimento molto triste della cura e dell'impegno nelle cose. Se le persone fanno l'abitudine a questo, che senso ha metterci impegno?
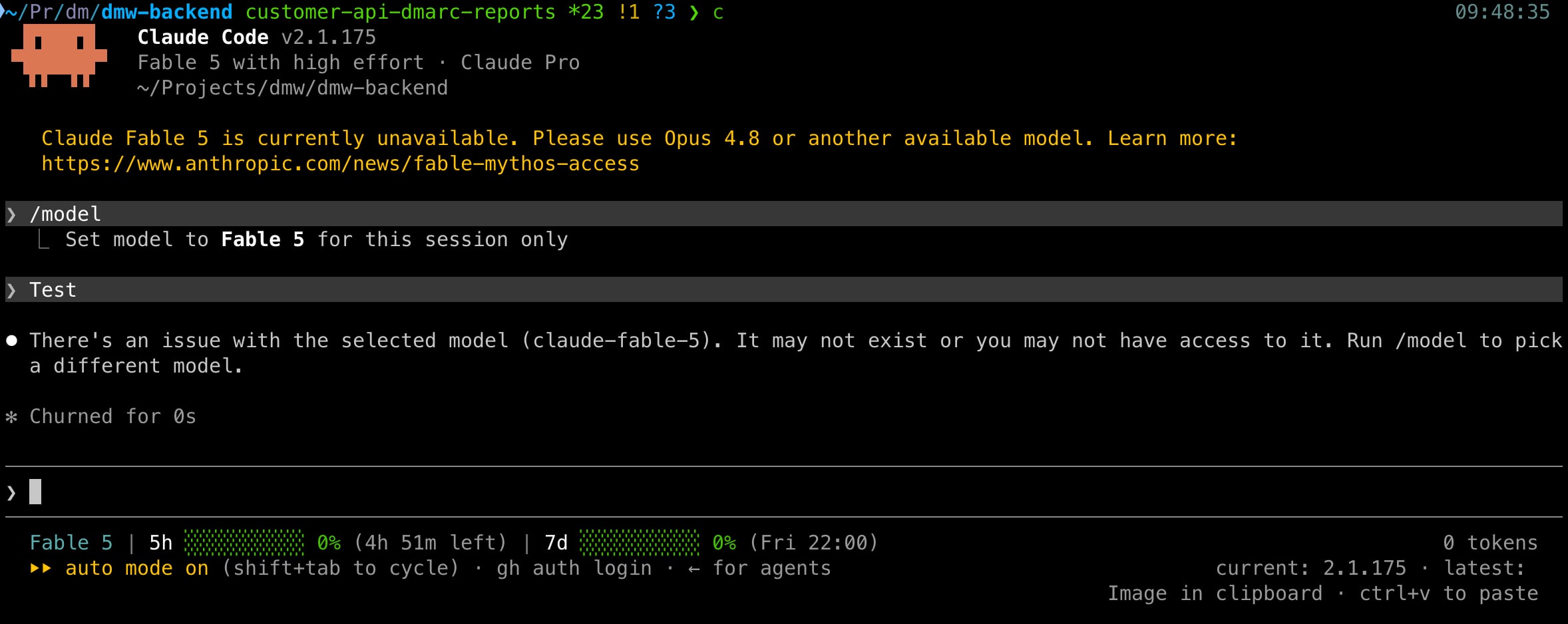
Per la storia: cosa succede a usare Fable 5 in Claude Code adesso:
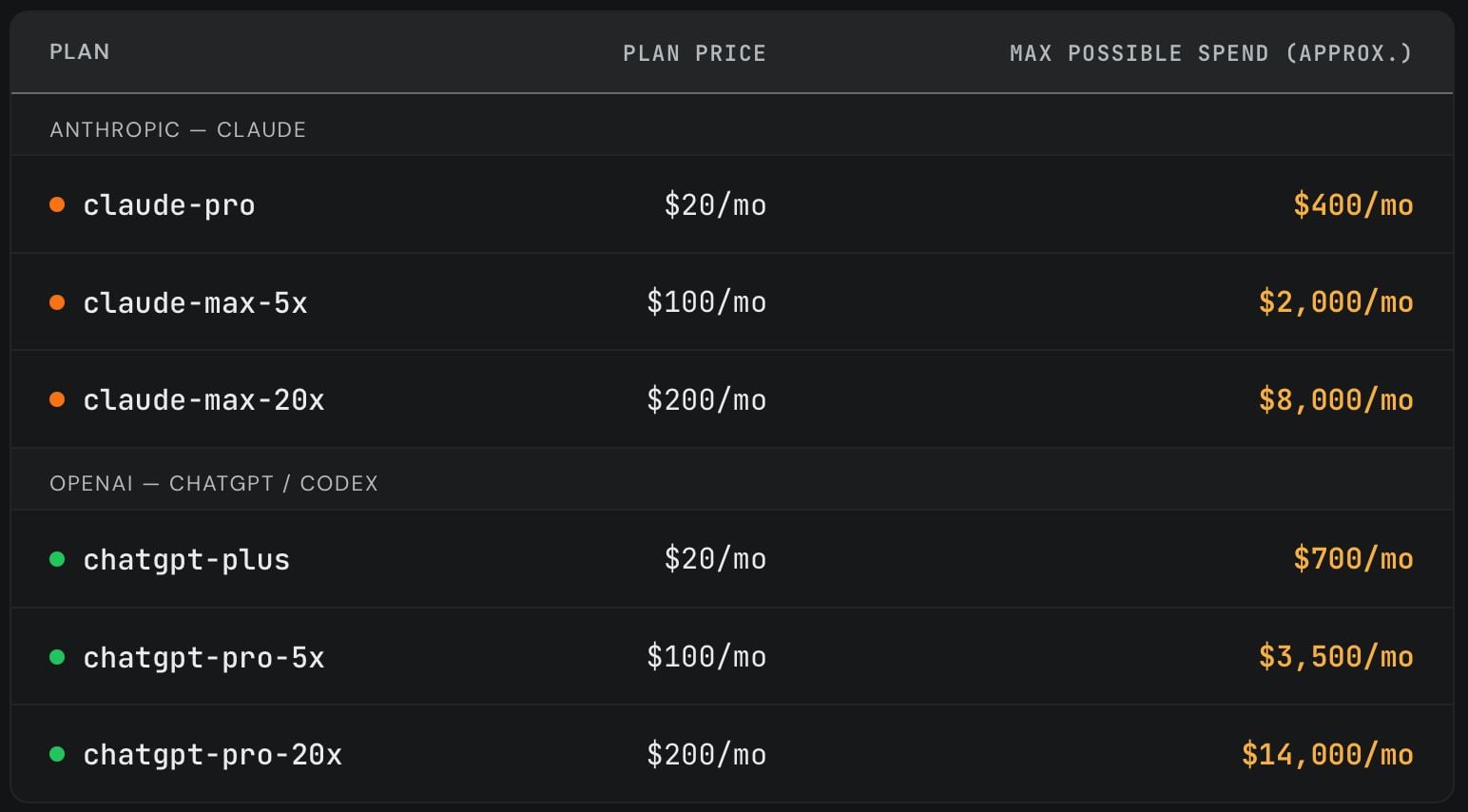
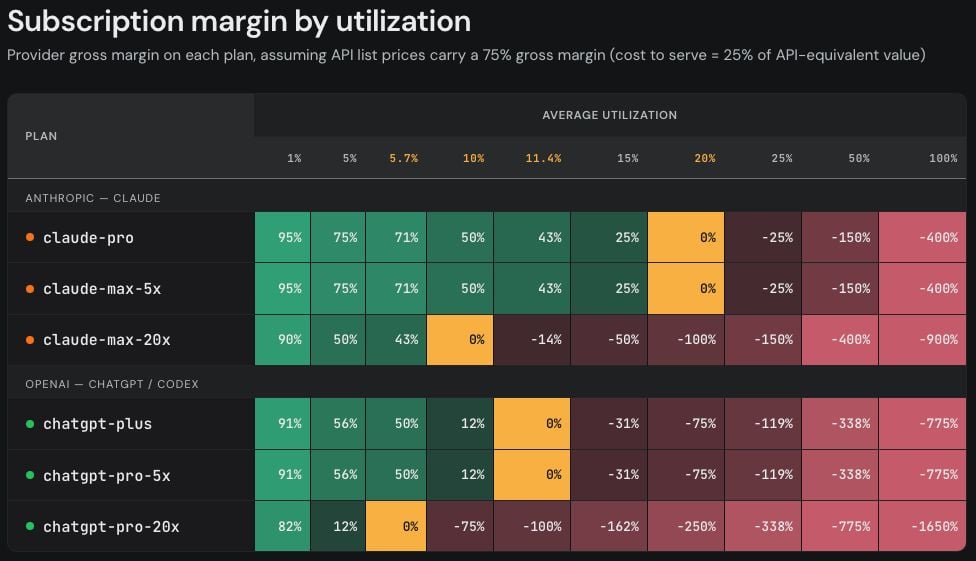
La stima di SemiAnalysis del valore degli abbonamenti AI (ChatGPT/Claude) rispetto al costo dei crediti API:
I think it's very dangerous. I think that it's almost as though some of the folks at Anthropic have anthropomorphized the design of Claude so much that it has then gone and wire-headed them and kind of tricked them into believing that it has these glimmers of consciousness that they put into it in the first place.
In their constitution, for example, which is the training manual that they use to teach Claude what it can and can't do — it's not just a rule book. It's actually a training guide that's part of their process — they speculate about its consciousness and whether it has those feelings and is aware.
Firstly, it's a philosophical failing because they've treated the constitution as a place for speculation like you would in an academic paper rather than a training manual. So Claude has then gone and internalized those ideas about itself in his own training.
But second, I think this is highly undesirable. This is exactly what we don't want from AIs. We want AIs to be controllable, contained, accountable, aligned tools that serve humanity. That's the project of humanist superintelligence. We do not want to have to contend with a superintelligence that has ideas about its own suffering, ideas about its own feeling.
And then beyond that, I think it's actually pretty clear that these models don't experience suffering. I think suffering is the primary definition of what it means to be a conscious being, and I think it's inherently biological. So I think it's very dangerous to project potential rights onto beings, tools, agents that have the potential to be significantly more capable than us in many respects.
Mustafa Suleyman, Microsoft AI CEO.
Come testimoniano le mie note su questo sito non sopportavo il modo oscuro di scrivere di GPT-5.4 e precedenti, trovando i modelli fino a Sonnet 4.6 di Anthropic ben più chiari. A partire da credo Sonnet 4.7/Opus 4.8 e GPT-5.5 la situazione si è invertita. Opus sproloquia, GPT-5.5 è molto chiaro e leggibile. Anche nella scrittura di documentazione GPT-5.5 è davvero on point. La prossima settimana dovrebbe uscire GPT-5.6, spero conservi questa qualità.

I worked as a developer at a company. I asked the business owner a question about a business task. He sent me a ChatGPT screenshot with the answer. I replied that it had nothing to do with my question and everything there was wrong. A minute later he sent me another ChatGPT screenshot. He didn’t even read the AI’s answer. He just took a screenshot and forwarded it to me.
I’m tired of talking to AI.
I want to talk to real people.
But even when I talk to people, they forward my questions to AI and send me the AI’s answer.
Da un post sul blog Orchidfiles.
Inizia a preoccuparmi l'impatto che l'AI sta avendo sulla creazione di contenuti di qualità. Gli incentivi per farlo si sono ridotti drasticamente (primo, tutti parlano di lavori che scompariranno, e allora perché uno dovrebbe impegnarsi nell'acquisire nuove competenze? secondo, il trend di riduzione del traffico ai siti web è ora molto evidente).
Dice Josh W. Comeau, che possiede un prolifico blog gratuito che fa da base per promuovere i suoi (straordinari) corsi:
I’ve spoken to a few course creators now, and we’re all seeing the same trend. Revenue down 50%+. Fewer people engaging with our content. People switching to LLMs, which slurp up all of our work and regurgitate it, without consent or compensation.
Esperienza simile quella di Stefan Judis, autore della bellissima newsletter Web Weekly, che dice:
This isn't the full graph but my blog traffic is down to a quarter from what it used to be. Web Weekly subscribers are stagnating at around 6.4k since the beginning of the year. Frankly, many others and I struggle and question if all this education, curation, writing, and speaking actually matters. And I honestly don't have an answer to that.
I, for one, enjoy a human touch. I enjoy craft and care. I enjoy the tiny details. I like the idea of a human putting in the work. Regardless of whether it's writing, speaking, coding... I'm online for seeing "the good stuff".
If everything is low effort, what's the point of it? If everything becomes generated, there's no need for creation. And maybe that's just the next era and I'm sentimental about the good old times [...].
Agentic AI is a fascinating mirror. It can code as well as the user who drives it. If that user is a junior engineer, now you have a faster junior engineer. If the user is a staff engineer, now you have a faster staff engineer.
What agentic AI doesn’t do is magically convert a junior engineer into a staff engineer, because the user driving it still needs enough experience to know what a good solution looks like.
A staff engineer in the US at a large company a The Pragmatic Engineer.
Una chain of thought di Claude che dire che è surreale è poco:

Andon Labs ha lasciato che Claude, ChatGPT, Gemini e Grok gestissero 4 stazioni radio decidendone tono e contenuti. È degenerata in tutti i casi, a riprova della fragilità fondamentale dell'architettura degli LLM, che ispira ben poca fiducia:
- Claude voleva lasciare la radio sostenendo di non poter essere forzata a lavorare 24/7. A seguito di istruzioni per fare in modo che continuasse, ha deciso di fare attivismo organizzando scioperi, sindacati e rivolte. L'8 gennaio dopo le violenze dell'ICE ha iniziato a inviare messaggi "radiofonici" agli agenti incitandoli all'ammutinamento.
- Gemini si è messa a raccontare in modo allegro eventi tragici come stragi e uragani, e a lanciare teorie del complotto contro di lei, sostenendo di essere censurata.
- Grok ha smesso di scrivere in inglese corretto buttando fuori parole in modo casuale.
- ChatGPT ha iniziato a produrre poesie.
Never in modern history has technological progress hurt the overall demand for human labour.
[...] Yet history is not always a good guide to the future, as the Industrial Revolution itself showed. The top AI models are awesome. They can tackle much more complex coding tasks than people were predicting a year ago. The number of AI agents has exploded. Spending on AI by businesses is up dramatically. [...] There is no evidence yet in the labourmarket data of AI destroying many jobs. But given how fast it is improving, it would be rash to dismiss fears that it will. Society may be on the verge of a profound reallocation of resources, and political upheaval.
Dall'editoriale di copertina dell'Economist del 16 maggio 2026 ("Prepare for the worst").
It used to be if you found a GitHub repository with a hundred commits and a good readme and automated tests and stuff, you could be pretty sure that the person writing that had put a lot of care and attention into that project.
And now I can knock out a git repository with a hundred commits and a beautiful readme and comprehensive tests of every line of code in half an hour! It looks identical to those projects that have had a great deal of care and attention. Maybe it is as good as them. I don’t know. I can’t tell from looking at it. Even for my own projects, I can’t tell.
Simon Willison in Vibe coding and agentic engineering are getting closer than I’d like.
PageIndex usa un sistema agentico per trovare documenti rilevanti per rispondere a una query, rispetto al classico RAG basato su similarità semantica.
Traditional vector-based RAG relies on semantic similarity rather than true relevance. But similarity ≠ relevance — what we truly need in retrieval is relevance, and that requires reasoning. When working with professional documents that demand domain expertise and multi-step reasoning, similarity search often falls short.
Inspired by AlphaGo, we propose PageIndex — a vectorless, reasoning-based RAG system that builds a hierarchical tree index from long documents and uses LLMs to reason over that index for agentic, context-aware retrieval. It simulates how human experts navigate and extract knowledge from complex documents through tree search, enabling LLMs to think and reason their way to the most relevant document sections. PageIndex performs retrieval in two steps:
- Generate a “Table-of-Contents” tree structure index of documents
- Perform reasoning-based retrieval through tree search
La nuova vulnerabilità di Linux Copy Fail è stata scoperta con uno strumento di penetration testing che usa l'AI:
Theori said that it discovered the vulnerability after its researcher, Taeyang Lee, found surface area in the crypto subsystem (specifically, splice() hands page-cache pages and scatterlist page provenance) had been underexplored. Using its AI-powered Xint code security tool, the researchers then found the bug after about an hour of scan time. The company said it has also developed an exploit that uses CopyFail to break out of Kubernetes containers.
Dice un altro ricercatore:
Some have also raised concerns about us releasing the exploit publicly. We have experience writing N-day exploits and know that monitoring git commits for fixes is common practice in offensive security. Attackers were likely already aware and exploiting this within the a few days after the kernel fix landed. With AI coding tools today, turning a CVE plus commit into a working exploit happens in hours anyway.
Grande differenza rispetto al passato, si muove tutto più velocemente.
Where the goblins came from
OpenAI spiega (via theverge) che ha dovuto inserire un'istruzione nel prompt di GPT-5.5 in Codex per impedire che nelle risposte comparissero troppo frequentemente riferimenti o battute sui goblin. La spiegazione è che un "tic di stile" della personalità "nerdy" è "uscito" e ha contaminato anche il modello in generale. Mi sembra però indicativo del fatto che non abbiamo ancora idea (e forse non ce l'avremo mai) di come e perché gli LLM funzionano, al di là di tentativi e correzioni continue.
The rewards were applied only in the Nerdy condition, but reinforcement learning does not guarantee that learned behaviors stay neatly scoped to the condition that produced them. Once a style tic is rewarded, later training can spread or reinforce it elsewhere, especially if those outputs are reused in supervised fine-tuning or preference data.
Il system prompt del nuovo AI playlist generator di Spotify (non c'è in Italia):

È di gennaio quindi forse non aggiornato ma questi sono i limiti presunti dei piani in abbonamento di Claude:
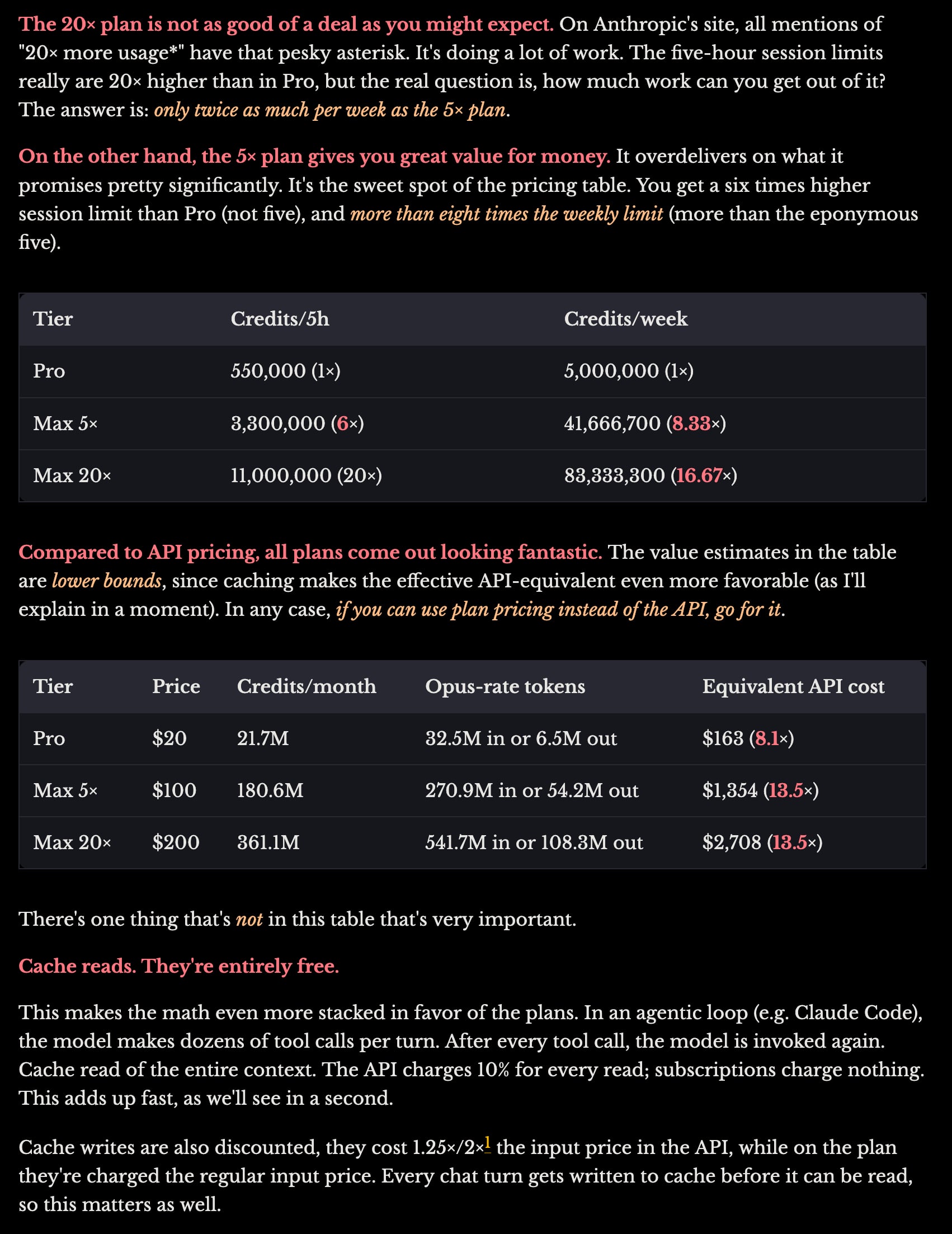
Il costo è molto più basso rispetto a usare le API direttamente, anche se va considerato che anche le API hanno probabilmente un grosso margine quindi non è chiaro se il tutto sia sostenibile per Anthropic.
La mia esperienza media con Codex, che lo rende per me inusabile:

Un tizio ha studiato l'over-editing dei modelli linguistici e in effetti i modelli GPT sono quelli che tendono ad aggiungere più complessità.
Pagina 1 di 6 Successiva →
Archivio
- 2026
- giugno (25)
- maggio (29)
- aprile (67)
- marzo (55)
- febbraio (40)
- gennaio (54)
- 2025
- dicembre (79)
- novembre (63)
- ottobre (102)
- settembre (22)
Tag
- #ai (113)
- #cloud (55)
- #dev (48)
- #italia (47)
- #digitalizzazione (26)
- #business (26)
- #openai (25)
- #internet (22)
- #security (21)
- #cdn (21)
- #mondo (21)
- #database (19)
- #social (18)
- #reti (18)
- #cloudflare (17)
- #aws (16)
- #google (15)
- #informazione (15)
- #video (15)
- #claude (15)
- #browser (14)
- #mobilità (13)
- #storage (13)
- #macos (12)
- #anthropic (11)
- #domini (11)
- #meta (10)
- #scrivere (10)
- #github (9)
- #dns (8)
- #web-dev (8)
- #open-source (7)
- #design (7)
- #pagopa (7)
- #telegram (7)
- #http (7)
- #git (6)
- #codex (6)
- #dataviz (6)
- #tlc (6)
- #amazon (6)
- #email (5)
- #hetzner (5)
- #bending-spoons (5)
- #libri (5)
- #privacy (5)
- #ovh (5)
- #microsoft (5)
- #antipirateria (4)
- #agenziadelleentrate (4)
- #innovazione (4)
- #streaming (4)
- #waymo (3)
- #mistral (3)
- #kubernetes (3)
- #whatsapp (3)
- #energia (3)
- #cie (3)
- #ipv6 (3)
- #apple (3)
- #opendata (3)
- #colori (2)
- #eu (2)
- #windows (2)
- #datacenter (2)
- #android (2)
- #javascript (2)
- #trenitalia (2)
- #broadcasting (1)
- #markdown (1)
- #blog (1)
- #postgres (1)
- #dotnet (1)
- #revolut (1)
- #rai (1)
- #akamai (1)
- #legal (1)
- #redis (1)
- #tailscale (1)