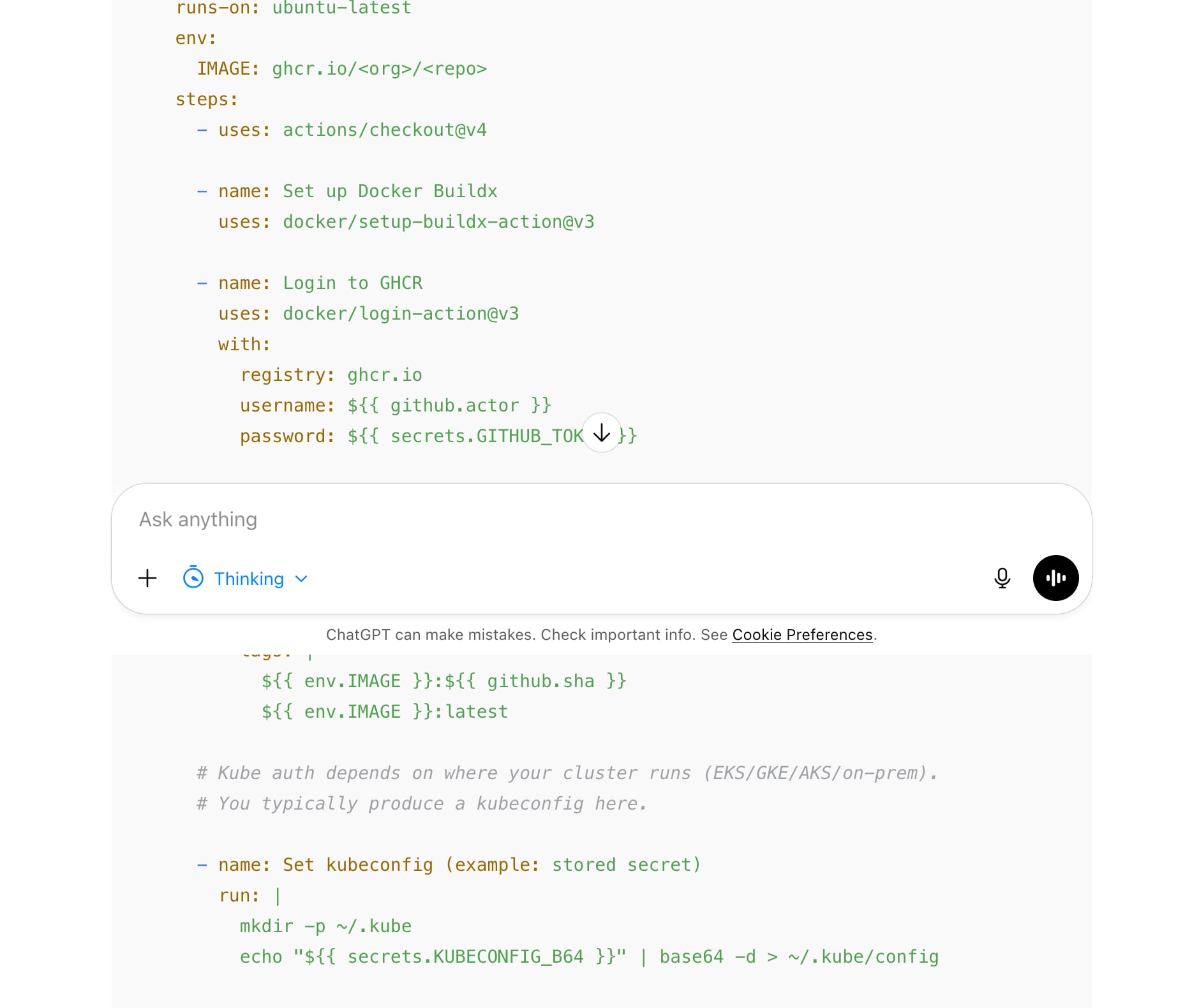
OpenAI ha pubblicato un articolo in cui spiega meglio la strategia di scaling di PostgreSQL: un server primario read-write e 50 replica read-only per supportare 800 milioni di utenti. Ma è di fatto in corso una migrazione verso database più scalabili come Azure Cosmos DB:
To mitigate these limitations and reduce write pressure, we’ve migrated, and continue to migrate, shardable (i.e. workloads that can be horizontally partitioned), write-heavy workloads to sharded systems such as Azure Cosmos DB, optimizing application logic to minimize unnecessary writes. We also no longer allow adding new tables to the current PostgreSQL deployment. New workloads default to the sharded systems.
Azure Cosmos DB è un database managed globalmente distribuito e a scalabilità essenzialmente illimitata, l'equivalente di DynamoDB di AWS ma, mi sembra di capire, con anche il supporto al modello relazionale e non solo NoSQL/a documenti (Azure Cosmos DB for PostgreSQL). Con garanzie di consistency che possono essere diverse da un classico database relazionale con scritture single-node, in base alla configurazione di sharding dell'estensione Citus.




.svg){kind=link}