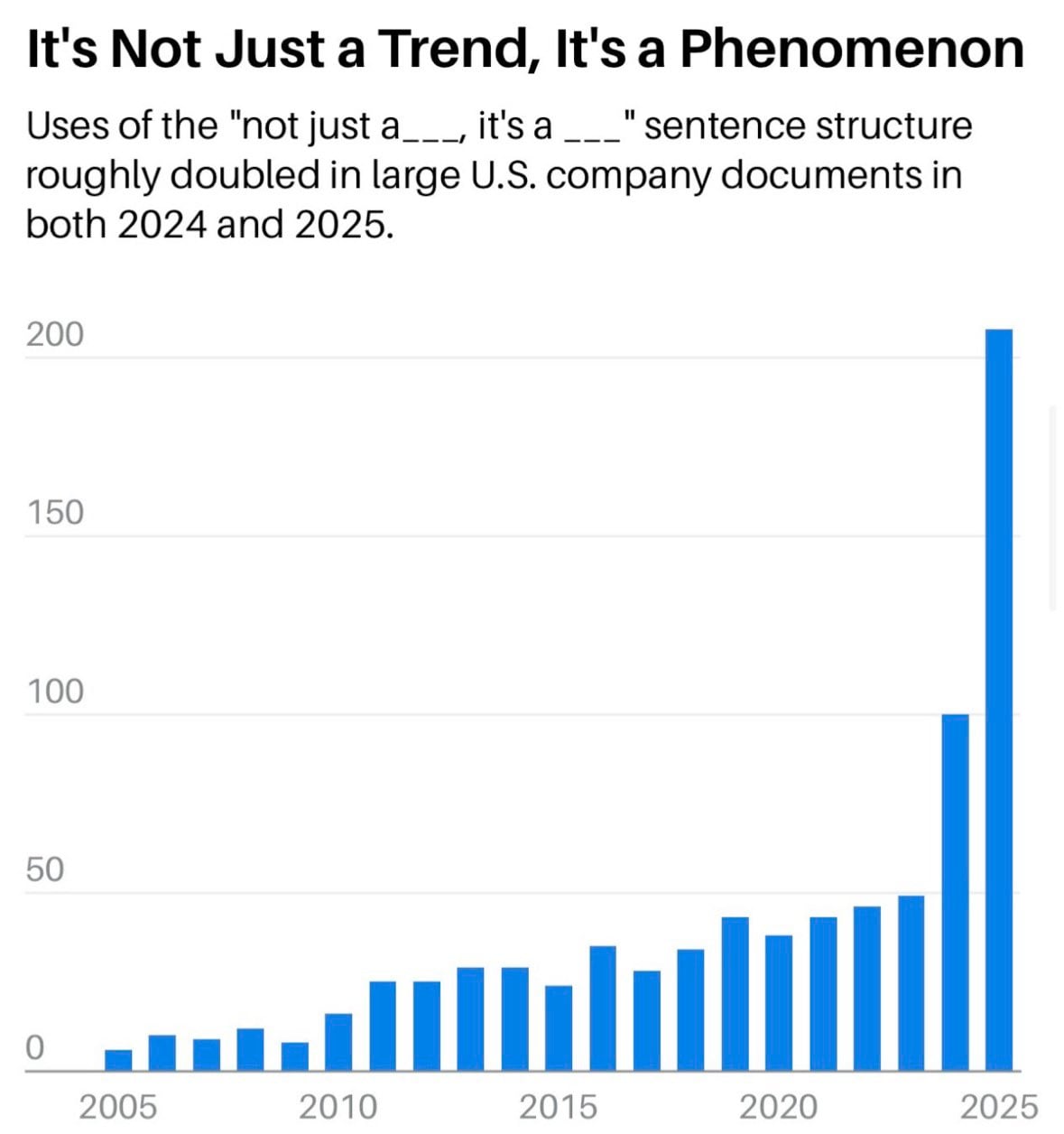
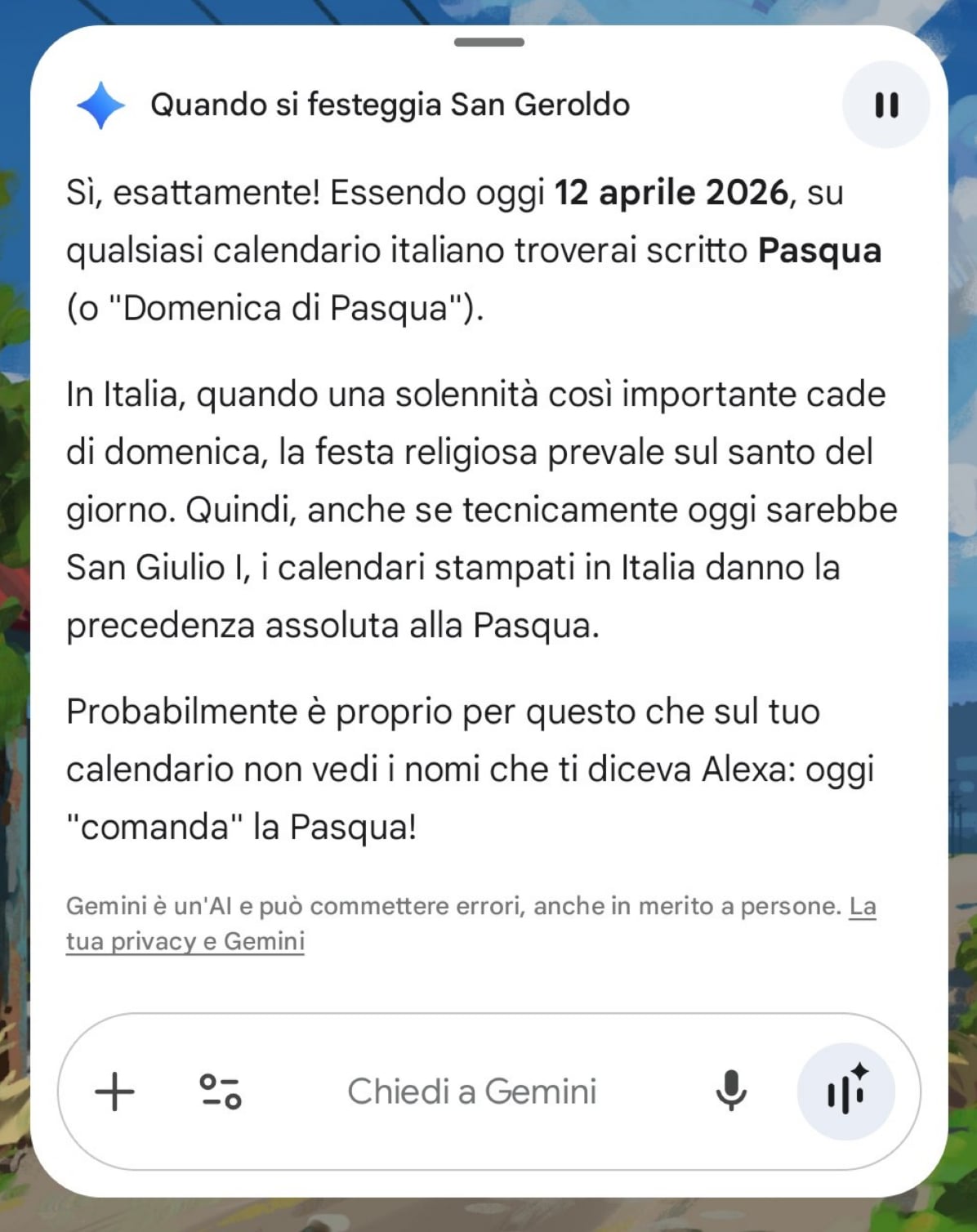
ChatGPT usa questa sintassi per le citazioni:
\uE200cite\uE082turn2search5\uE201
Oppure con due citazioni:
\uE200cite\uE082turn2search5\uE082turn2news1\uE201
Dove i simboli Unicode sono "caratteri" privati invisibili usati così:
- Inizio:
U+E200
- Separatore:
U+E082
- Fine:
U+E201
Scelta interessante.
Gli ID (es. turn2search5) sono presi direttamente dall'output dei tool, ad esempio:
{
"search_results": [
{
"ref_id": "turn2search0",
"title": "Eiffel Tower history",
"url": "https://example.com/eiffel-history"
},
{
"ref_id": "turn2search1",
"title": "Britannica - Eiffel Tower",
"url": "https://example.com/britannica-eiffel"
},
{
"ref_id": "turn2search2",
"title": "Paris tourism - Eiffel Tower",
"url": "https://example.com/paris-tourism"
}
]
}
Mistral sembra invece usare questa sintassi:
:refs[1-3,7,9]
Dove 3, 7 e 9 sono indici della lista di risultati di un tool, l'1 non so cosa sia.
Esempio di tool output:
{
"0": {
"url": "https://trytako.com/embed/OQENsP2y2BMZd8fnd6oa/",
"title": "Unit Calculator: 330.0 Inchs to Meters",
"description": "Questa scheda mostra la conversione da Pollice a Metro...",
"snippets": [],
"date": null,
"rank": 0,
"source": "tako",
"metadata": {},
"can_open": false,
"content_type": "tako_widget"
},
"1": {
"url": "https://www.vacanzeparigine.it/torre-eiffel/",
"title": "Come visitare la torre Eiffel - Vacanze Parigine",
"description": "Gli altri piani rimarranno disponibili alla visita... secondo piano: a 115,88 metri d’altezza e 669 scalini.",
"snippets": [
"CHIUSURA: a causa di lavori di manutenzione la cima della torre Eiffel (il terzo piano) rimarrà chiusa dal 5 gennaio al 6 febbraio 2026 (info). Gli altri piani rimarranno disponibili alla visita. INCREMENTO TARIFFARIO: il costo dei biglietti subirà un aumento a partire dalle visite dal 12 gennaio 2026 in poi. ... secondo piano: a 115,88 metri d’altezza e 669 scalini.",
"Considerando l’antenna, la torre Eiffel raggiunge i 330 metri d’altezza..."
],
"date": "2026-01-12T08:22:43",
"rank": 0,
"source": "brave",
"metadata": {},
"can_open": true,
"content_type": "web_page"
},
}
Claude usa invece questa sintassi più esplicita:
<cite index="2-1">Label</cite>
Dove 2 sarebbe il documento di riferimento mentre 1 la frase citata. Quindi si possono citare più frasi e anche più documenti:
<cite index="2-1:3">Label</cite>
<cite index="1-2,3-4">Label</cite>
Gli indici sono estratti dagli output dei tool, ad esempio:
<document index="2">
<source>La Torre Eiffel, Sito UFFICIALE: biglietti, info, notizie,…</source>
<document_content>
<span index="2-1">Alta 330 metri, la Torre Eiffel ha una storia affascinante
che risale alla fine del XIX secolo. Il suo progettista, l'ingegnere Gustave
Eiffel, era famoso per la realizzazione di ponti, viadotti e capriate
metalliche, già prima di costruire ...</span>
</document_content>
</document>