Le aspirazioni di Railway per essere una startup ancora piccola sono incredibili. Qua spiegano come hanno costruito in pochi mesi una CDN Anycast con 60 POP e 30M RPS, qua come gestiscono l'inventario dei server anche con l'aiuto dell'AI, qua la nuova generazione di hardware per le location compute. Ormai sono sulla strade per competere con Cloudflare.
7 giugno 2026
6 giugno 2026
Stop Using Conventional Commits. Ah, finalmente ho trovato il mio club. I conventional commit sono inutili nella maggior parte dei casi.
4 giugno 2026
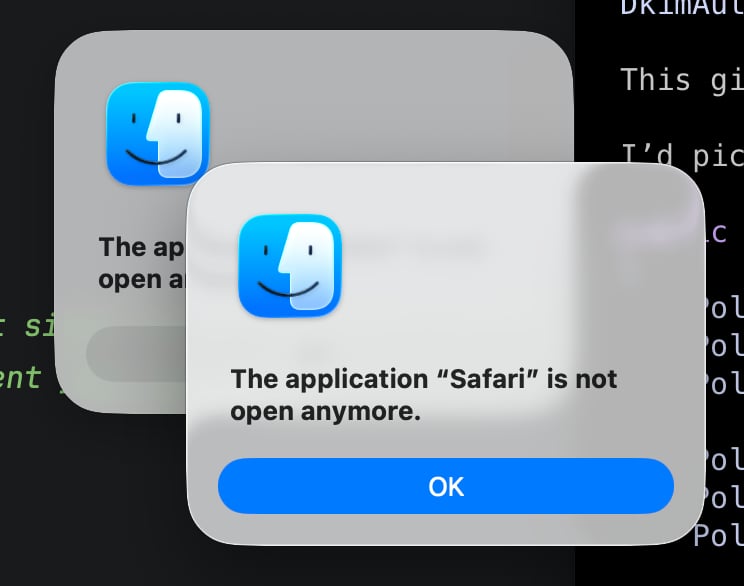
Ogni volta che chiudo Safari, il Finder mi avvisa (?):
L’Italia non soffre di una cronica mancanza di risorse. Soffre di una cronica incapacità di scegliere. Lo vediamo nel sistema fiscale, appesantito da centinaia di agevolazioni e regimi speciali spesso inefficaci; nel sistema degli incentivi alle imprese, diventato un labirinto che ha sostituito la politica industriale con la frammentazione; nella difficoltà di affrontare temi come la concorrenza, le concessioni, il mercato immobiliare, le pensioni o la semplificazione amministrativa senza cedere a pressioni corporative. Troppo spesso la politica preferisce distribuire eccezioni invece di costruire regole. Bonus, condoni, deroghe e sussidi finiscono per sostituire le riforme. Il Superbonus 110 per cento rappresenta probabilmente il caso più clamoroso: una misura costosissima, dagli effetti sociali e ambientali molto inferiori alle aspettative, che ha mostrato quanto sia facile spendere risorse e quanto sia difficile produrre trasformazioni.
Pina Picierno in Picierno ci spiega perché lascia il Pd.
1 giugno 2026

31 maggio 2026
Riassuntone delle nuove regole europee sulla riparabilità e sulle batterie:
In 2023, the European Union agreed on two landmark pieces of legislation mandating how portable tech products with batteries must be designed, aiming to improve longevity, repairability, and recyclability. Commission Regulation (EU) 2023/1670 came into force last year and applies specifically to smartphones and tablets, while Regulation (EU) 2023/1542 takes effect next year and covers almost every other piece of technology with a battery inside.
The wider rules, which kick in from February 18th, 2027, are simple: Users must be able to remove and replace batteries with basic tools, or specialized tools that are provided with the product for free, and compatible spare batteries must be sold for at least five years. The tool requirement means swapping the battery doesn’t need to be as simple as popping off a clip-on cover, but can’t be much more complicated than removing a few standard screws. The regulation applies to headphones, e-readers, portable game consoles, laptops, and more. If it’s got a battery, it’s probably covered.
There are a few exemptions. Smartphones and tablets are the big two, simply because they’re already covered by that other law, which requires manufacturers to make a variety of spare parts for phones available for at least seven years. Some of those parts need only be available to professional repairers, but others must be provided to end users, and must be designed to be replaceable by a layman with basic tools. Batteries are covered by that requirement, but with a specific, and important, exemption: If a battery still has 83 percent capacity after 500 charging cycles, 80 percent after 1,000 cycles, and the device has an IP67 rating, then battery replacement can be limited only to professionals. Essentially, if your phone is waterproof, and its battery will last at least three years with minimal capacity loss, then it doesn’t need to be user replaceable. For years there was ambiguity about how these two sets of regulations would interact, but in a notice published last year the EU confirmed that the existing smartphone and tablet rules “prevail over” the new, wider regulations.
Continua su The Verge (The Stepback).
#511 /
15:15
28 maggio 2026
Da Hacker News, una lista di tool carini basati sui dati Last.fm:
https://lastfmviz.netlify.app/ - shows what you've been listening to as a grid of album covers. You can scroll down as long as you want. It's cool to look back and remember where I was when listening to specific music.
https://lastfmstats.com/ - generates tons of rankings, line charts, racing bar charts, etc. A couple I like: "Artist streaks" (I listened to Pavement tracks 122 times in a row in August 2023), "Unique artists in a single month" (225 in July 2025) and "Unique weeks per artist/album/track" (good to identify what you're always listening to vs. what you listened to heavily in a specific time)
https://pmcdonough8133.github.io/last.timer/ - shows your listening rankings by hours, minutes instead of just scrobble count. This really should be a default feature in the site, as some artists have average track length 2-3x times of others.
Stupendo anche LastWave.
I worked as a developer at a company. I asked the business owner a question about a business task. He sent me a ChatGPT screenshot with the answer. I replied that it had nothing to do with my question and everything there was wrong. A minute later he sent me another ChatGPT screenshot. He didn’t even read the AI’s answer. He just took a screenshot and forwarded it to me.
I’m tired of talking to AI.
I want to talk to real people.
But even when I talk to people, they forward my questions to AI and send me the AI’s answer.
Da un post sul blog Orchidfiles.
27 maggio 2026
Inizia a preoccuparmi l'impatto che l'AI sta avendo sulla creazione di contenuti di qualità. Gli incentivi per farlo si sono ridotti drasticamente (primo, tutti parlano di lavori che scompariranno, e allora perché uno dovrebbe impegnarsi nell'acquisire nuove competenze? secondo, il trend di riduzione del traffico ai siti web è ora molto evidente).
Dice Josh W. Comeau, che possiede un prolifico blog gratuito che fa da base per promuovere i suoi (straordinari) corsi:
I’ve spoken to a few course creators now, and we’re all seeing the same trend. Revenue down 50%+. Fewer people engaging with our content. People switching to LLMs, which slurp up all of our work and regurgitate it, without consent or compensation.
Esperienza simile quella di Stefan Judis, autore della bellissima newsletter Web Weekly, che dice:
This isn't the full graph but my blog traffic is down to a quarter from what it used to be. Web Weekly subscribers are stagnating at around 6.4k since the beginning of the year. Frankly, many others and I struggle and question if all this education, curation, writing, and speaking actually matters. And I honestly don't have an answer to that.
I, for one, enjoy a human touch. I enjoy craft and care. I enjoy the tiny details. I like the idea of a human putting in the work. Regardless of whether it's writing, speaking, coding... I'm online for seeing "the good stuff".
If everything is low effort, what's the point of it? If everything becomes generated, there's no need for creation. And maybe that's just the next era and I'm sentimental about the good old times [...].
25 maggio 2026
AudioMass è un editor audio multitraccia gratuito e open source che funziona nel browser.
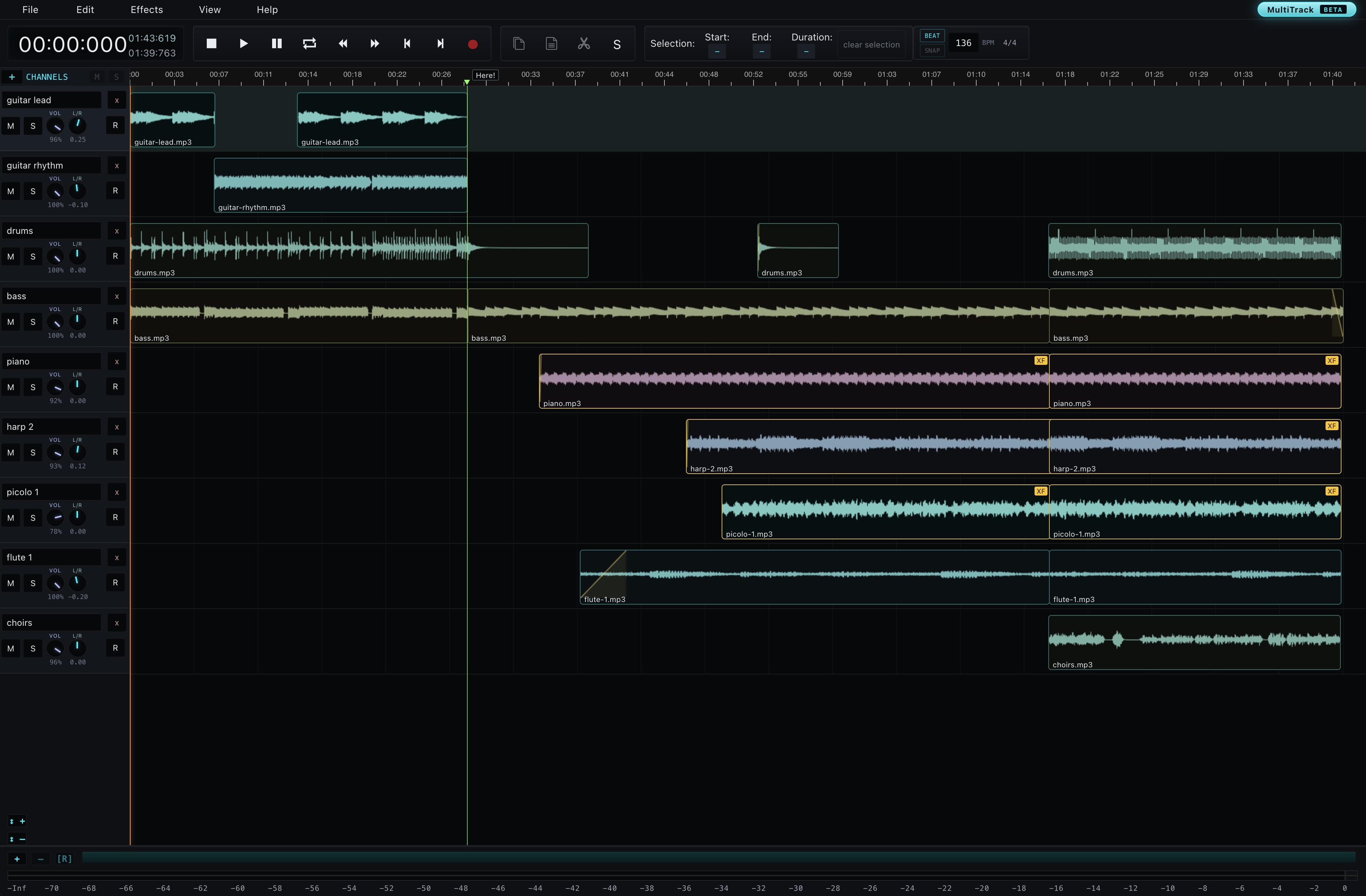
#507 /
09:24
21 maggio 2026
Agentic AI is a fascinating mirror. It can code as well as the user who drives it. If that user is a junior engineer, now you have a faster junior engineer. If the user is a staff engineer, now you have a faster staff engineer.
What agentic AI doesn’t do is magically convert a junior engineer into a staff engineer, because the user driving it still needs enough experience to know what a good solution looks like.
A staff engineer in the US at a large company a The Pragmatic Engineer.
20 maggio 2026
Una chain of thought di Claude che dire che è surreale è poco:

In Italia il cliente non ha sempre ragione. Si è inceppata la concorrenza che porta al miglioramento del servizio ai client?
Uscito da queste esperienze mi sono chiesto: perché i commercianti italiani possono permettersi di guardare dall’alto in basso i clienti? Perché si sentono spesso in una posizione di autorità anziché di servizio? Le imprese cercano profitti, quindi hanno bisogno di clienti contenti. Dovrebbero trattarli bene. E noi clienti, se trattati male, dovremmo andarcene. La concorrenza dovrebbe fare il suo lavoro: premiare chi ci rispetta, punire chi ci umilia.
Railway e le avventure con Google Cloud:
Around 22:20 UTC, our Google Cloud account was placed into a "restricted" status hence removing all of our cloud overflow VMs, our CloudSQL instance, and our API. In removing our API, it removed a central dependency that affected all GCP host workloads, and then after our network route cache expired, then affecting all workloads hosted on the Railway platform.
19 maggio 2026
Questi 13 prodotti Google hanno ciascuno più di 1 miliardo di utenti:

Google Search, Gmail, Android, Chrome e YouTube hanno ciascuno più di 3 miliardi di utenti:

Presumo si intenda utenti attivi mensili.
Gli utenti attivi di Gemini sono invece 900 milioni, quindi si presume più di ChatGPT.
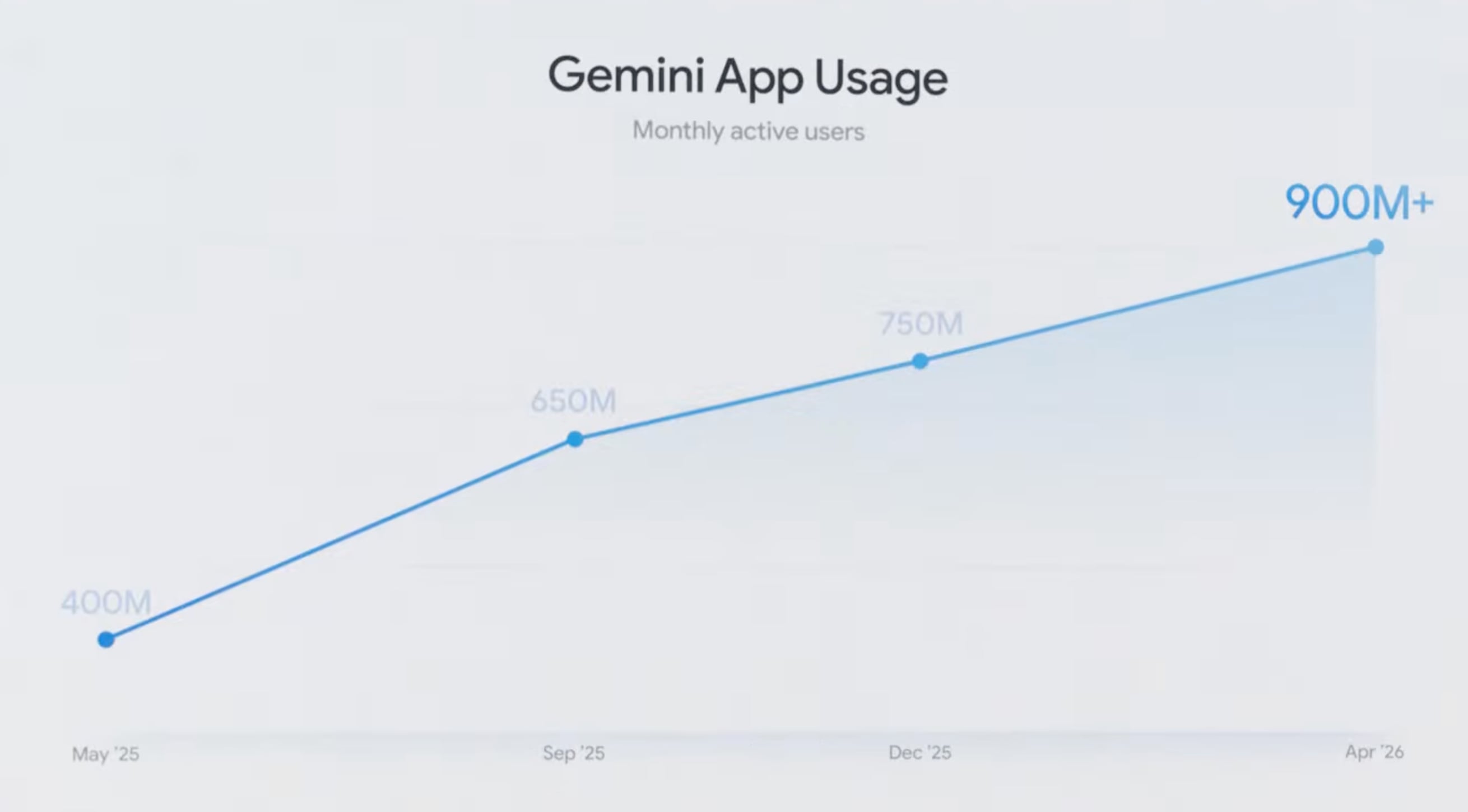
Da Google I/O.
16 maggio 2026
Andon Labs ha lasciato che Claude, ChatGPT, Gemini e Grok gestissero 4 stazioni radio decidendone tono e contenuti. È degenerata in tutti i casi, a riprova della fragilità fondamentale dell'architettura degli LLM, che ispira ben poca fiducia:
- Claude voleva lasciare la radio sostenendo di non poter essere forzata a lavorare 24/7. A seguito di istruzioni per fare in modo che continuasse, ha deciso di fare attivismo organizzando scioperi, sindacati e rivolte. L'8 gennaio dopo le violenze dell'ICE ha iniziato a inviare messaggi "radiofonici" agli agenti incitandoli all'ammutinamento.
- Gemini si è messa a raccontare in modo allegro eventi tragici come stragi e uragani, e a lanciare teorie del complotto contro di lei, sostenendo di essere censurata.
- Grok ha smesso di scrivere in inglese corretto buttando fuori parole in modo casuale.
- ChatGPT ha iniziato a produrre poesie.
Never in modern history has technological progress hurt the overall demand for human labour.
[...] Yet history is not always a good guide to the future, as the Industrial Revolution itself showed. The top AI models are awesome. They can tackle much more complex coding tasks than people were predicting a year ago. The number of AI agents has exploded. Spending on AI by businesses is up dramatically. [...] There is no evidence yet in the labourmarket data of AI destroying many jobs. But given how fast it is improving, it would be rash to dismiss fears that it will. Society may be on the verge of a profound reallocation of resources, and political upheaval.
Dall'editoriale di copertina dell'Economist del 16 maggio 2026 ("Prepare for the worst").
15 maggio 2026
Regarding Bob Greene’s “From TV Dinners to Smartphones” (op-ed, May 13): Please don’t blame the 1950s TV dinner for today’s screen addiction. I was a 1980s latchkey kid, and some of my favorite memories involved coming home from school, choosing something to heat up from the freezer and watching family sitcom reruns.
My adolescent children’s experience is society’s desecration of that way of life, not an evolution from it. Today, mobile devices endlessly spew entertainment that rarely models healthy social behavior. By contrast, shows like “The Brady Bunch” reinforced to young viewers, especially those from dysfunctional families, what healthy relationships and communication look like. I would welcome technology that brings back some of that warmth and positivity.
Una lettera al Wall Street Journal.
It used to be if you found a GitHub repository with a hundred commits and a good readme and automated tests and stuff, you could be pretty sure that the person writing that had put a lot of care and attention into that project.
And now I can knock out a git repository with a hundred commits and a beautiful readme and comprehensive tests of every line of code in half an hour! It looks identical to those projects that have had a great deal of care and attention. Maybe it is as good as them. I don’t know. I can’t tell from looking at it. Even for my own projects, I can’t tell.
Simon Willison in Vibe coding and agentic engineering are getting closer than I’d like.
Raycast 2
La nuova architettura cross-platform di Raycast 2 è tecnicamente impressive. La UI diventa una web view ma è talmente polished che è sostanzialmente indistinguibile.
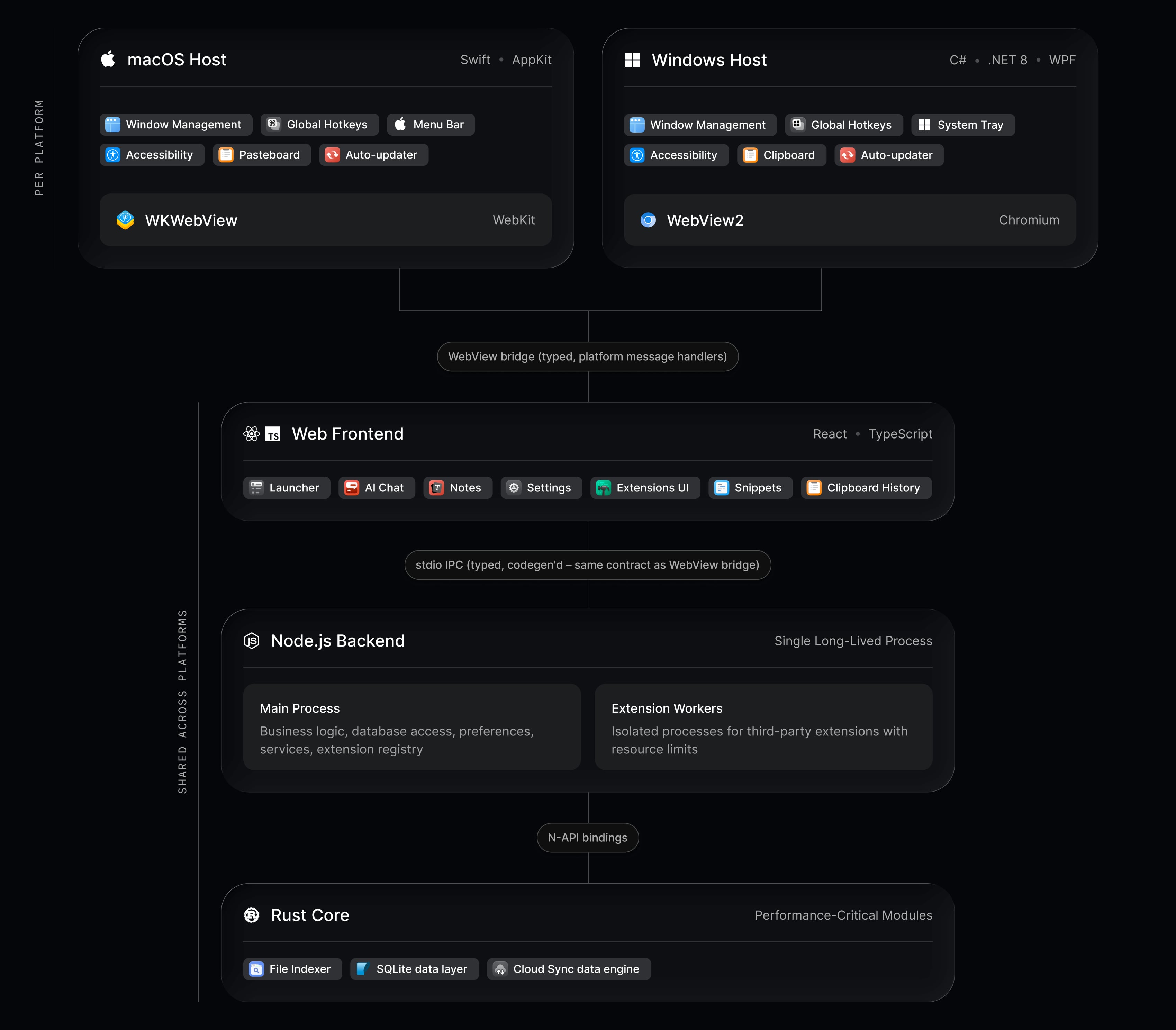
#497 /
14:07
Archivio
- 2026
- giugno (25)
- maggio (29)
- aprile (67)
- marzo (55)
- febbraio (40)
- gennaio (54)
- 2025
- dicembre (79)
- novembre (63)
- ottobre (102)
- settembre (22)
Tag
- #ai (113)
- #cloud (55)
- #dev (48)
- #italia (47)
- #digitalizzazione (26)
- #business (26)
- #openai (25)
- #internet (22)
- #security (21)
- #cdn (21)
- #mondo (21)
- #database (19)
- #social (18)
- #reti (18)
- #cloudflare (17)
- #aws (16)
- #google (15)
- #informazione (15)
- #video (15)
- #claude (15)
- #browser (14)
- #mobilità (13)
- #storage (13)
- #macos (12)
- #anthropic (11)
- #domini (11)
- #meta (10)
- #scrivere (10)
- #github (9)
- #dns (8)
- #web-dev (8)
- #open-source (7)
- #design (7)
- #pagopa (7)
- #telegram (7)
- #http (7)
- #git (6)
- #codex (6)
- #dataviz (6)
- #tlc (6)
- #amazon (6)
- #email (5)
- #hetzner (5)
- #bending-spoons (5)
- #libri (5)
- #privacy (5)
- #ovh (5)
- #microsoft (5)
- #antipirateria (4)
- #agenziadelleentrate (4)
- #innovazione (4)
- #streaming (4)
- #waymo (3)
- #mistral (3)
- #kubernetes (3)
- #whatsapp (3)
- #energia (3)
- #cie (3)
- #ipv6 (3)
- #apple (3)
- #opendata (3)
- #colori (2)
- #eu (2)
- #windows (2)
- #datacenter (2)
- #android (2)
- #javascript (2)
- #trenitalia (2)
- #broadcasting (1)
- #markdown (1)
- #blog (1)
- #postgres (1)
- #dotnet (1)
- #revolut (1)
- #rai (1)
- #akamai (1)
- #legal (1)
- #redis (1)
- #tailscale (1)