TIL esiste un indice di leggibilità dei testi italiani chiamato Gulpease:
L'Indice Gulpease è un indice di leggibilità di un testo tarato sulla lingua italiana. Rispetto ad altri ha il vantaggio di utilizzare la lunghezza delle parole in lettere anziché in sillabe, semplificandone il calcolo automatico.
Qua un calcolatore online.
Idempotency Is Easy Until the Second Request Is Different. Deep dive nell'implementazione di idempotency nelle API HTTP.
Quindi: il prodotto che TeamSystem ha sviluppato in casa per quarant’anni cresce del 5%. Il prodotto che TeamSystem ha messo insieme comprando startup negli ultimi dieci anni cresce del 24%.
Quasi cinque volte tanto.
Questo lo confermano le parole del CEO Federico Leproux, in più di un’intervista:
“La nostra strategia consiste nel puntare fortemente sull’open innovation al fine di acquisire esternamente know-how, soluzioni innovative e skill che sarebbero difficili da sviluppare internamente.”
Tradotto: noi compriamo l’innovazione perché farla in casa è troppo difficile. Il CEO lo dice apertamente: è la strategia ufficiale.
Giulio Michelon in TeamSystem ha un sacco di debito.
Si avvicina il momento in cui si potranno pagare i tributi attualmente pagabili con F24 anche con pagoPA. Finalmente.
PageIndex usa un sistema agentico per trovare documenti rilevanti per rispondere a una query, rispetto al classico RAG basato su similarità semantica.
Traditional vector-based RAG relies on semantic similarity rather than true relevance. But similarity ≠ relevance — what we truly need in retrieval is relevance, and that requires reasoning. When working with professional documents that demand domain expertise and multi-step reasoning, similarity search often falls short.
Inspired by AlphaGo, we propose PageIndex — a vectorless, reasoning-based RAG system that builds a hierarchical tree index from long documents and uses LLMs to reason over that index for agentic, context-aware retrieval. It simulates how human experts navigate and extract knowledge from complex documents through tree search, enabling LLMs to think and reason their way to the most relevant document sections. PageIndex performs retrieval in two steps:
- Generate a “Table-of-Contents” tree structure index of documents
- Perform reasoning-based retrieval through tree search
A ogni carattere che scrivo, questo:
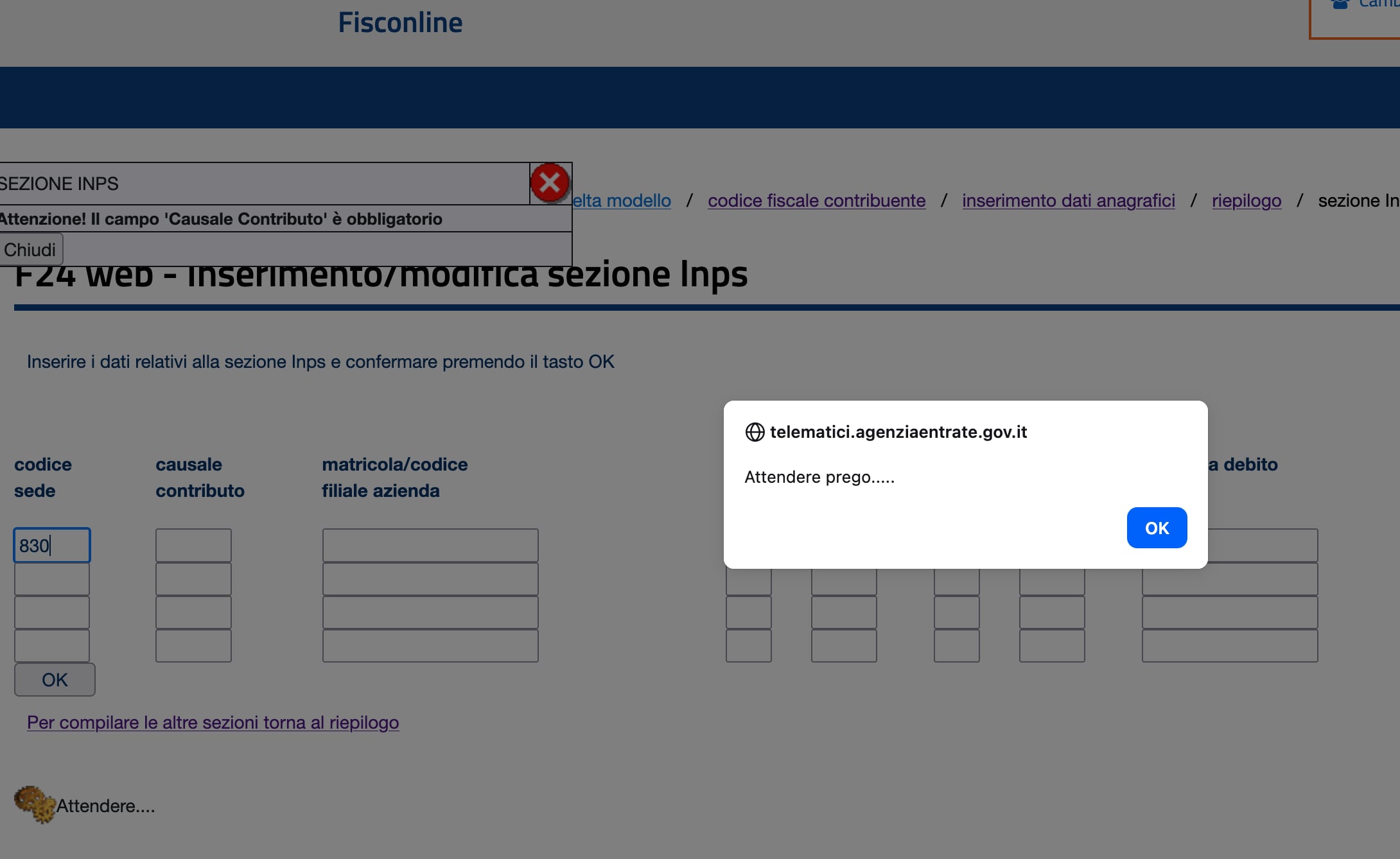
La nuova app Trenitalia sembra bella, ma crasha nella pagina più importante cioè "I miei viaggi", dove ci sono i biglietti.
Apri il sito Trenitalia e il testo "CIRCOLAZIONE REGOLARE SULLA RETE ALTA VELOCITÀ" inizia a scorrere al contrario quindi non vedi mai il testo completo se non stai attento:

La nuova vulnerabilità di Linux Copy Fail è stata scoperta con uno strumento di penetration testing che usa l'AI:
Theori said that it discovered the vulnerability after its researcher, Taeyang Lee, found surface area in the crypto subsystem (specifically, splice() hands page-cache pages and scatterlist page provenance) had been underexplored. Using its AI-powered Xint code security tool, the researchers then found the bug after about an hour of scan time. The company said it has also developed an exploit that uses CopyFail to break out of Kubernetes containers.
Dice un altro ricercatore:
Some have also raised concerns about us releasing the exploit publicly. We have experience writing N-day exploits and know that monitoring git commits for fixes is common practice in offensive security. Attackers were likely already aware and exploiting this within the a few days after the kernel fix landed. With AI coding tools today, turning a CVE plus commit into a working exploit happens in hours anyway.
Grande differenza rispetto al passato, si muove tutto più velocemente.
Nel 2013 BNP Paribas lancia Hello bank! — una delle prime banche 100% mobile d'Europa. Prima ancora di Revolut. Prima di N26. Oggi Revolut e N26 sono i riferimenti del settore. Hello bank! li insegue. Come si perde un vantaggio in pochi anni? Ho vissuto quella storia dall'interno, in Italia, fino al 2019. E la risposta che ho trovato non riguarda la tecnologia, né il prodotto. Riguarda come si accompagna il cambiamento quando è ancora fragile. Un'innovazione che funziona dentro una grande organizzazione ha bisogno di tre cose: spazio per crescere con parametri propri, risorse coerenti con l'orizzonte temporale del progetto, e qualcuno che la difenda quando i risultati di breve periodo premono nella direzione opposta. Quando manca una di queste tre cose, il progetto non muore di colpo. Si spegne lentamente — mentre l'organizzazione continua a credere di sostenerlo. Chi oggi guida una trasformazione digitale ha davanti esattamente questa sfida. Non basta avere l'idea giusta, né le persone giuste. Bisogna costruire le condizioni perché quelle persone possano davvero guidare il cambiamento — e tenerle al riparo dalle logiche di breve che, in ogni organizzazione, sono sempre più forti di quanto sembri.
La domanda che ho imparato a pormi da quel momento in poi: stiamo costruendo qualcosa, o stiamo solo gestendo la transizione verso il prossimo budget review?
Matteo Coppari, lead di Hello bank! 2013-2021 in un post LinkedIn.
Non uso più Windows ma notevole il nuovo Win+R di Windows 11:
Faster than before: Perf was top-of-mind when rewriting Run, and with a 94ms median time-to-show time it’s faster than ever before (more on how we got there below)!
- The existing dialog median time-to-show is 103ms
- The browse button has very low usage. 0.0038% of users have clicked that button with a sample of 35 million.
- Validated users do use the dialog to paste text from the clipboard, then copy it again without running anything to scrub text formatting.
Canonical (Ubuntu) sotto attacco DDoS con i servizi online che non funzionano da ieri proprio mentre la vulnerabilità Copy Fail è stata svelata ed è per ora unpatched. L'attacco è stato rivendicato da "Islamic Cyber Resistance in Iraq – 313 Team".
~ ❯ dig ubuntu.com
; <<>> DiG 9.20.22 <<>> ubuntu.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 5065
;; flags: qr rd ra; QUERY: 1, ANSWER: 3, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 512
;; QUESTION SECTION:
;ubuntu.com. IN A
;; ANSWER SECTION:
ubuntu.com. 38 IN A 185.125.190.20
ubuntu.com. 38 IN A 185.125.190.21
ubuntu.com. 38 IN A 185.125.190.29
;; Query time: 9 msec
;; SERVER: 8.8.8.8#53(8.8.8.8) (UDP)
;; WHEN: Fri May 01 14:38:59 CEST 2026
;; MSG SIZE rcvd: 87
~ ❯ curl -I https://ubuntu.com
curl: (56) Recv failure: Connection reset by peer
~ ❯ ipinfo 185.125.190.20
Core
- IP 185.125.190.20
- Anycast false
- Hostname website-content-cache-1.ps5.canonical.com
- City London
- Region England
- Country United Kingdom (GB)
- Currency GBP (£)
- Location 51.5085,-0.1257
- Organization AS41231 Canonical Group Limited
- Postal E1W
- Timezone Europe/London
È iniziato il nuovo round di assegnazione delle nuove gTLD. L'ultimo era stato nel 2012. Le candidature costano 227mila dollari e resteranno aperte dal 30 aprile al 12 agosto. In autunno sapremo la lista.
FastCGI: 30 Years Old and Still the Better Protocol for Reverse Proxies. Andrew Ayer di SSLMate spiega in occasione del 30° anniversario di FastCGI come il protocollo sia per certi versi (e almeno in teoria) migliore di HTTP per la comunicazione tra reverse proxy e backend.
FastCGI is very usable today, and has been in production use at SSLMate for over 10 years. That said, using a vintage technology has some downsides. It was never updated to support WebSockets. The tooling is not as good. For example, curl has no way to make requests to a FastCGI server. It supports FTP, Gopher, and even SMTP (however that works), but not FastCGI. When I benchmarked Go's FastCGI server behind a variety of reverse proxies, some workloads had worse throughput compared to HTTP/1.1 or HTTP/2. I don't think that's inherent to the protocol, but a reflection that FastCGI code paths have not been optimized as much as HTTP.
OpenAI spiega (via theverge) che ha dovuto inserire un'istruzione nel prompt di GPT-5.5 in Codex per impedire che nelle risposte comparissero troppo frequentemente riferimenti o battute sui goblin. La spiegazione è che un "tic di stile" della personalità "nerdy" è "uscito" e ha contaminato anche il modello in generale. Mi sembra però indicativo del fatto che non abbiamo ancora idea (e forse non ce l'avremo mai) di come e perché gli LLM funzionano, al di là di tentativi e correzioni continue.
The rewards were applied only in the Nerdy condition, but reinforcement learning does not guarantee that learned behaviors stay neatly scoped to the condition that produced them. Once a style tic is rewarded, later training can spread or reinforce it elsewhere, especially if those outputs are reused in supervised fine-tuning or preference data.
Leggo cose buone su RWX, nuova piattaforma di CI/CD pensata per velocizzare i processi nell'era dell'AI engineering, con parallelizzazione automatica, esecuzione delle pipeline prima del commit e altre ottimizzazioni.
Big tech, dipendenze e tribunali. Lungo, interessante e documentato articolo sui punti di vista attuali della scienza sugli effetti dei social network sulla salute mentale. La conclusione che inaspettatamente si sta confermando con gli studi più recenti è che l'effetto negativo sulla salute mentale non è dovuto ai social perché gli effetti misurati sono solitamente minimi:
Viviamo in una condizione di stress persistente — lavorativo, economico, esistenziale — che il capitalismo contemporaneo produce quotidianamente e per la quale cerchiamo sollievo momentaneo nello scrolling, esattamente come le generazioni precedenti cercavano sollievo nella televisione spazzatura. Il design della piattaforma conta, certo, ma conta meno delle condizioni materiali di vita. E riconoscerlo significherebbe spostare il bersaglio dalle scelte di design di Zuckerberg alle scelte politiche che rendono le nostre vite così stressanti da farci desiderare la fuga. Ma questo, evidentemente, è un discorso che non conviene a nessuno — né alle piattaforme, né ai loro accusatori.
Questa tesi è contraria a quella dominante nell'ultimo decennio, oggetto di molti libri e documentari (es. The Social Dilemma) e della recente sentenza negli USA, secondo cui il problema sia invece il design dei social studiati per creare questa forma di dipendenza. Sarà proprio per questo motivo che a primo impatto questa teoria sembra ben poco convincente. Eppure gli effetti del TikTok di turno sull'attenzione a me sembrano palesi e quindi mi sembra strida un po' con la realtà che vediamo attorno.
Contento però di aver sentito questo recap del punto di vista scientifico. Food for thought.
Alessio Butti, mentre consolida l'uso del sito del dipartimento per la trasformazione digitale come megafono per diffondere praticamente solo le sue frequenti interviste in cui ripete sempre le stesse cose, ora dice, parlando di connettività in fibra:
Rimediamo ai disastri ereditati dagli altri governi
Insomma è sempre colpa di quella di prima, anche dopo una legislatura intera. Anche quando quelli prima erano loro stessi (governo Draghi, sostenuto anche dalla destra).
Anche quando il nuovo bando di gara che dovrebbe risolvere i problemi ha non solo gli stessi difetti dei precedenti, ma ne ha pure di nuovi e incomprensibili. Ma tanto non sarà sua responsabilità difendere i risultati.
A proposito della vicenda di cronaca nera che partendo dalle mie parti si è diffusa in tutta Italia è impossibile non notare il solito cortocircuito. Prima i media diffondono particolari macabri e inquietanti, virgolettati attribuiti all’ambulanziere sospettato degli omicidi di anziani pazienti, “prove” che non solo suggeriscono la colpevolezza dell’imputato ma ne disegnano i tratti di morbosa anomalia e che inevitabilmente coinvolgono molto delle persone intorno a lui, e poi, quando l’effetto atteso di una vasta indignazione (e di pagine viste e copie vendute) è stato ottenuto, iniziano a produrre la seconda onda: articoli sugli effetti a cascata che l’indignazione social ha prodotto sulle persone vicine all’imputato, quelle stesse persone che gli stessi media avevano ampiamente coinvolto. Come se le minacce social non fossero l’effetto inevitabile del cattivo giornalismo e delle sue intenzionali attenzioni ai particolari più inquietanti. Come ogni volta ciò che i media producono non è solo cattiva informazione ma anche una lesione ampia del senso di comunità. Cattiveria indotta come modello economico residuo che ha come effetto principale quello di mettere i cittadini gli uni contro gli altri.
Massimo Mantellini in Giornalismo come lesione.