Dati interessanti su Setlist.fm:
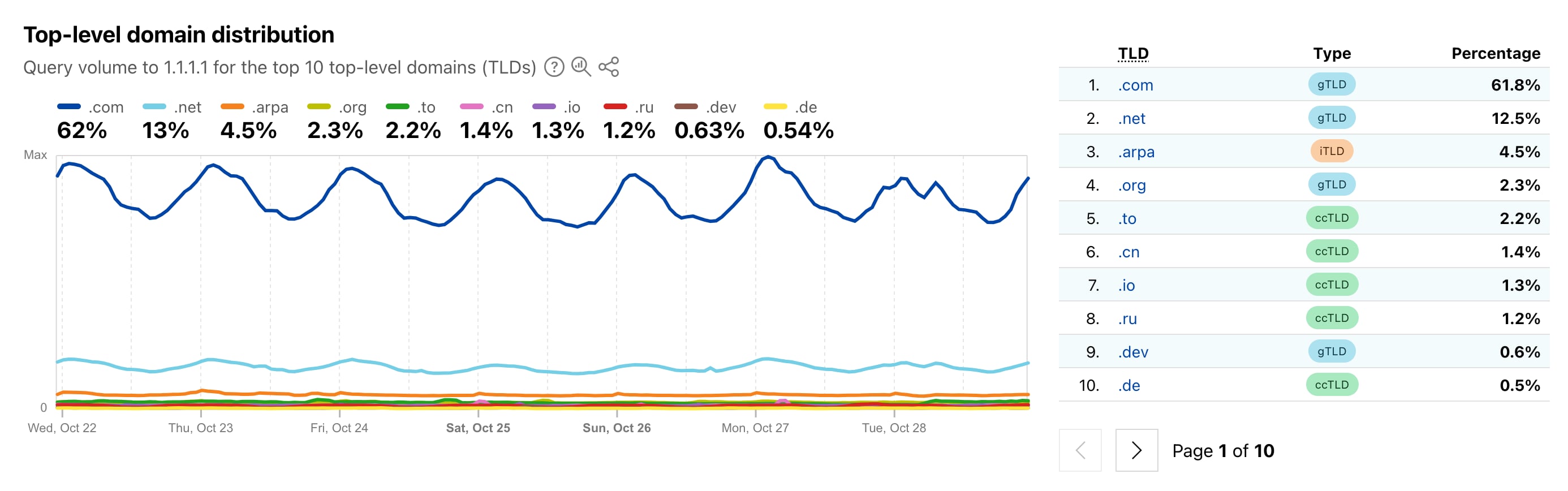
Show by show, user entry by user entry, Setlist.fm exploded. In 2012, the site had a database of more than 400,000 set lists for 24,000 artists and reached 1.5 million people a month. Now, it has more than 9 million set lists for 400,000 artists, with 80 million users a year, according to Live Nation. Someone creates a new set list every 20 seconds. Fleischer emphasized that people stay on the site for an average of roughly eight minutes: “It’s a really heavily engaged community.”
Setlist.fm carries advertisements, but that income probably accounted for only a tiny portion of the $896 million in profit its parent company, Live Nation, posted last year. A corporate behemoth, Live Nation is the world’s largest concert promoter and the owner of Ticketmaster. The company does not break out revenue or earnings for Setlist.fm.
(NYT)