E’ nata la risposta Europea sulla guida autonoma: @niulinx
Dopo molti mesi di lavoro è iniziata la più difficile sfida professionale della mia vita.
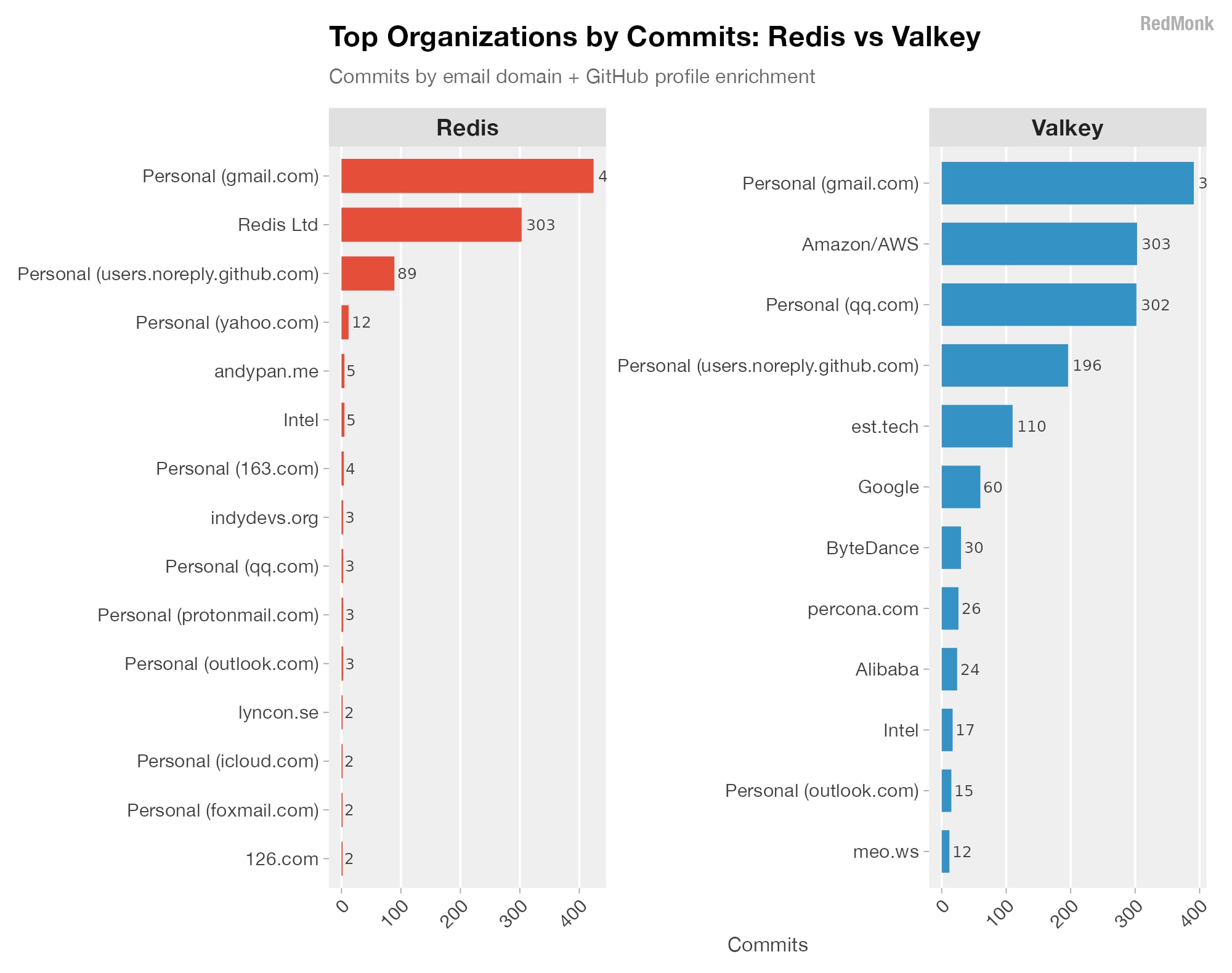
38M€ per il primo round, @gruppo_a2a
e il fondo AI di CDP Cassa Depositi e Prestiti come lead investors e con il contributo fondamentale di un parterre di investitori come: AFL (Famiglia Falck), @fsitaliane
, @Pirelli
, VC Partners SGR, MOST, Fondazione ICO Falck, @EmilioFrazzoli
, Stefano Bernardi
Niulinx è uno spinoff del @polimi
dal gruppo di ricerca AIDA del Prof. @sergiosavaresi
Il Team
Io sono il CEO, Cristiano Bonetti il CTO e Gian Marco Felice il CFO e Presidente del Board.
12 Fondatori e oltre 60 tra PhD, Ingegneri elettronici, meccanici, nucleari, matematici, informatici e Fisici. L’età media delle persone che vi lavorano è 27 anni.
Un comitato tecnico di assoluta eccellenza presieduto dal Prof. Sergio Savaresi
Cosa fa Niulinx
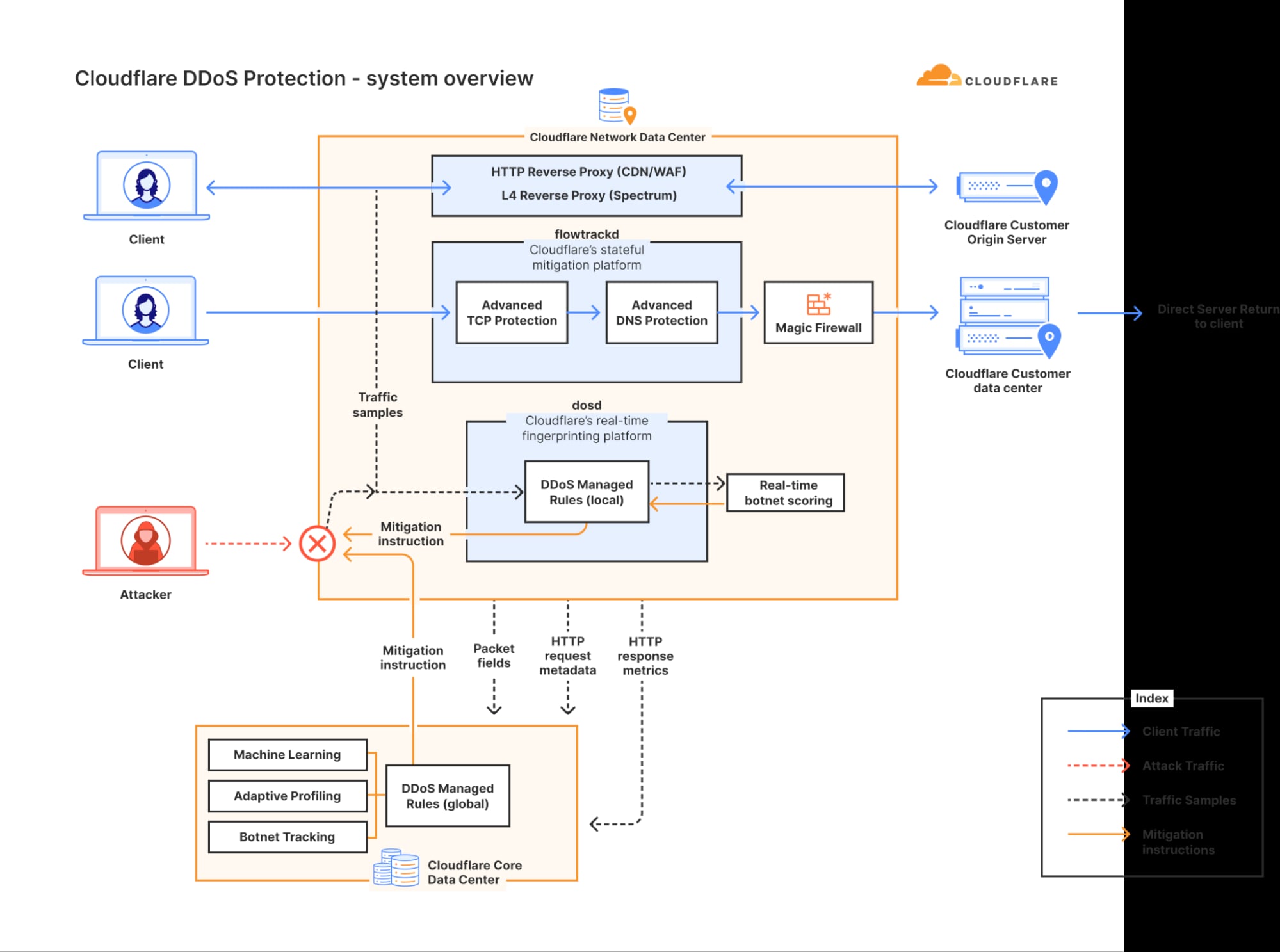
Niulinx sviluppa l’intero sistema tecnologico che rende possibile la guida autonoma: dalla percezione dell’ambiente alla pianificazione del percorso, dal controllo del veicolo alla gestione remota della flotta.
I nostri obiettivi sono:
1-Omologare automobili a guida autonoma in Europa entro 3 anni per erogare un servizio su flotte condivise
2-Creare una istituzione Europea con massa critica di ingegneri capaci di sviluppare in Europa la tecnologia sulla guida autonoma in tutti i suoi casi d’uso rilevanti
Perché ora, perché l’Europa
Il mercato globale della guida autonoma vale oggi oltre 50 miliardi di dollari e si prevede superi i 300 miliardi entro il 2035. Mentre Stati Uniti e Cina hanno diversi players l’Europa non ha ancora un campione continentale. Niulinx nasce per colmare questo vuoto: non replicando il modello americano, ma costruendo un approccio industriale europeo – regulatory-first, capital-efficient, e progettato per scalare attraverso un modello di franchising con operatori locali.
Una coalizione industriale senza precedenti
La compagine degli investitori rappresenta una convergenza unica dell’industria italiana della mobilità, dell’energia e delle infrastrutture:
A2A – primo investimento diretto di A2A Life Ventures, braccio di innovazione del Gruppo, nella strategia di Corporate Venture Capital per la mobilità autonoma e sostenibile.
CDP Venture Capital – partecipa attraverso il Fondo Artificial Intelligence
AFL, Ferrovie dello Stato Italiane, Pirelli, VC Partners SGR con il fondo VC Partners Fund I, MOST, Fondazione ICO Falck – completano il round con competenze nell’energia, nei materiali avanzati, nelle infrastrutture di trasporto, nel venture capital e nella ricerca sulla mobilità sostenibile. A questi si aggiungono Emilio Frazzoli (già CTO di nuTonomy/Motional, oggi Professore all’ETH di Zurigo) e Stefano Bernardi, investitori individuali di profilo internazionale.
Siamo salpati, vediamo ora dove ci porterà la nostra determinazione e capacità mentre navighiamo in un mondo complesso