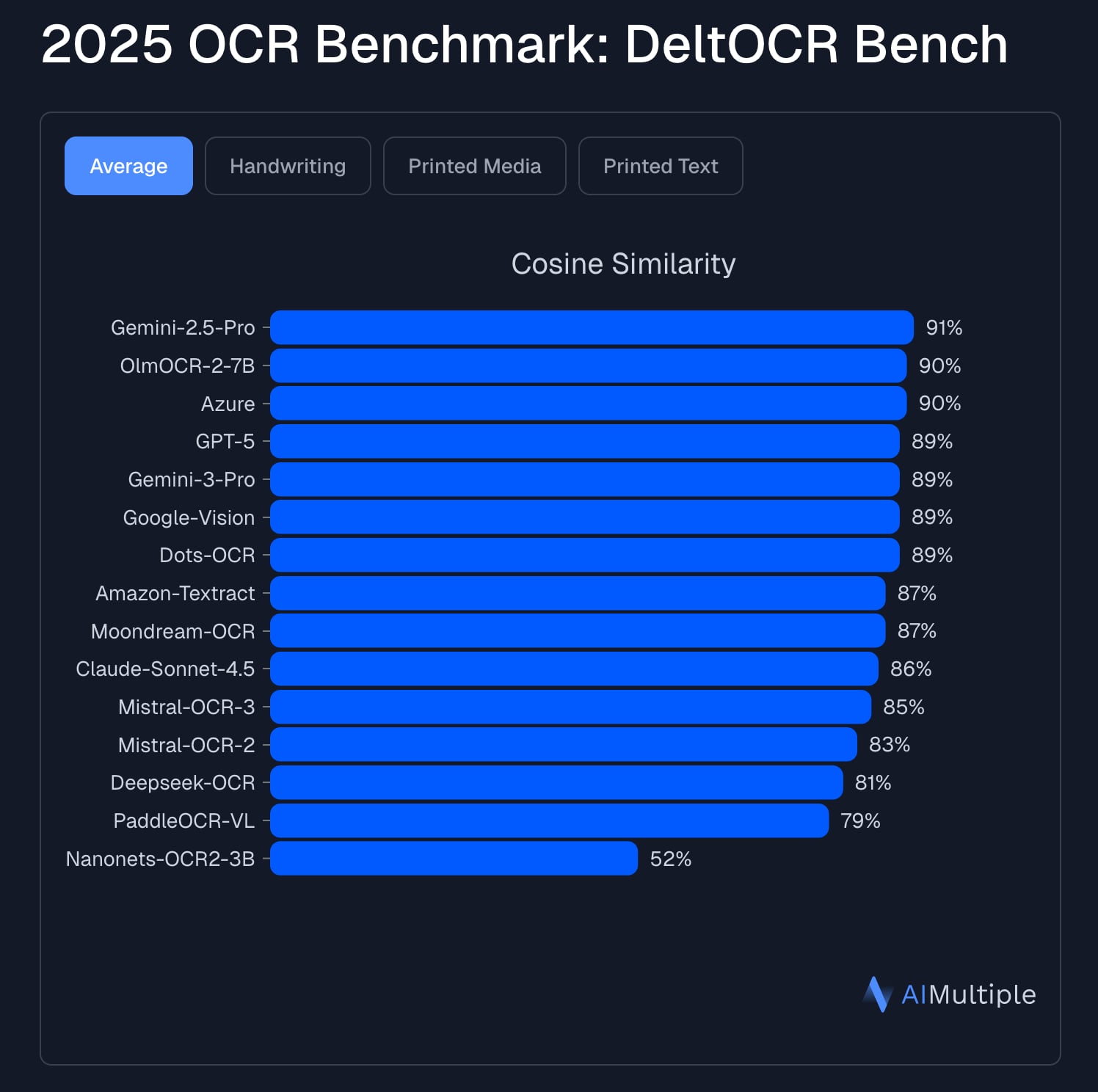
L'azienda dietro Tailwind CSS è in crisi perché con l'AI nessuno compra più il pacchetto di componenti, che era la principale fonte di ricavi per pagare il team:
But the reality is that 75% of the people on our engineering team lost their jobs here yesterday because of the brutal impact AI has had on our business. And every second I spend trying to do fun free things for the community like this is a second I'm not spending trying to turn the business around and make sure the people who are still here are getting their paychecks every month.
Traffic to our docs is down about 40% from early 2023 despite Tailwind being more popular than ever. The docs are the only way people find out about our commercial products, and without customers we can't afford to maintain the framework. I really want to figure out a way to offer LLM-optimized docs that don't make that situation even worse (again we literally had to lay off 75% of the team yesterday), but I can't prioritize it right now unfortunately, and I'm nervous to offer them without solving that problem first.
[...]
Tailwind is growing faster than it ever has and is bigger than it ever has been, and our revenue is down close to 80%. Right now there's just no correlation between making Tailwind easier to use and making development of the framework more sustainable. I need to fix that before making Tailwind easier to use benefits anyone, because if I can't fix that this project is going to become unmaintained abandonware when there is no one left employed to work on it. I appreciate the sentiment and agree in spirit, it's just more complicated than that in reality right now.
(GitHub)