Dopo l'acquisizione di Vodafone Italia da parte di Swisscom il 1° gennaio 2025, dal 1° gennaio 2026 la società Vodafone Italia S.p.A. sarà incorporata in Fastweb S.p.A, assieme a VEI srl che gestisce Ho. Mobile. Il brand resta per ora ma andrà a scomparire entro 4 anni (il quinto è già andato).
4 dicembre 2025
E alla fine MinIO versione community è improvvisamente abbandonato. Ci è voluto poco.

3 dicembre 2025
Ottimizzazioni di un'altra era nell'app Facebook:
In 2012 we took this wild ride at mobile infra at Facebook when trying to reduce the several-seconds long load time for “Newsfeed”. A few people worked on different approaches. Something we quickly realized was that setting up a connection with TCP and TLS was incredibly slow on mobile networks at the time. The fix was to have just one, keep it alive and multiplex. Shaved a whole second off. But it was still slow. Several people were convince that us sending JSON was the problem, so two different teams started to work on compact binary encoding. After a lot of experimentation what actually worked out best was to send JSON with ordered fields and a compile-time generated parser. Turns out both our iOS and Android app would do something silly like: 1) read all JSON data from server into a buffer, 2) decode that buffer with a generic JSON decoder into lists & dicts, 3) traverse those structures and build the final struct/class tree. Oh and another neat thing we eventually did—when the network connection needed to be setup—was to send an optimistic UDP packet to the server saying “get started fetching data for the following query”; once the real connection was established, TLS handshake completed and user session authenticated, the response was already ready to be sent back.
Costo dell'energia elettrica nel 2024
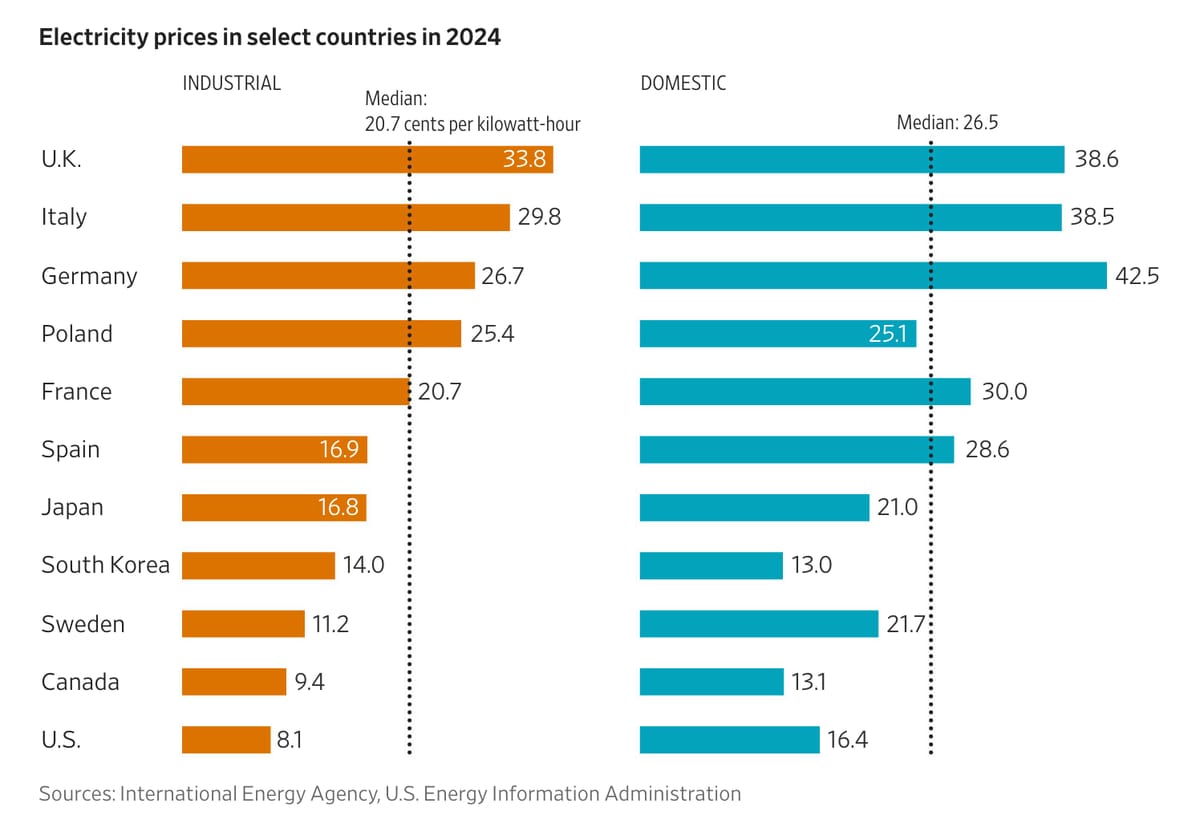
In questo articolo di Hardware Upgrade qualche foto della loro visita nel datacenter OVHcloud di Parigi (il primo con 3 AZ).
Gli spazi nelle RFC
There are three forms of whitespace:
o WSP represents simple whitespace, i.e., a space or a tab character (formal definition in [RFC5234]).
o LWSP is linear whitespace, defined as WSP plus CRLF (formal definition in [RFC5234]).
o FWS is folding whitespace. It allows multiple lines separated by CRLF followed by at least one whitespace, to be joined.
The formal ABNF for these are (WSP and LWSP are given for information only):
WSP = SP / HTAB LWSP = *(WSP / CRLF WSP) FWS = [WSP CRLF] 1WSP
The definition of FWS is identical to that in [RFC5322] except for the exclusion of obs-FWS.
(fonte)
#195 /
10:21
2 dicembre 2025
It seems so rude and careless to make me, a person with thoughts, ideas, humor, contradictions and life experience to read something spit out by the equivalent of a lexical bingo machine because you were too lazy to write it yourself.
Pablo Enoc in It's insulting to read your AI-generated blog post
#193 /
17:11
CloudFront ora supporta mTLS (mutual TLS authentication con certificato client) senza costi aggiuntivi. Molto interessante.
S3 server access logs at scale. Yelp spiega come usa e gestisce grandi quantità di log di accesso a S3, su S3.
Nuova vita per JPEG XL, che forse arriverà in Chrome e Firefox con la nuova implementazione in Rust.
- Lossless re-compression of JPEG images. This means you can re-compress your current JPEG library without losing information and benefit from a ~30% reduction in file size for free. This is a killer feature that no other format has.
- Support for wide gamut and HDR.
- Support for image sizes of up to 1,073,741,823x1,073,741,824. You won’t run out of image space anytime soon. AVIF is ridiculous in this aspect, capping at 8,193x4,320. WebP goes up to 16K, while the original 1992 JPEG supports 64K.
- Maximum of 32 bits per channel. No other format (except for the defunct JPEG 2000) offers this.
- Maximum of 4,099 channels. Most other formats support 4 or 5, with the exception of JPEG 2000, which supports 16,384.
- JXL is super resilient to generation loss.
- JXL supports progressive decoding, which is essential for web delivery, IMO. WebP or HEIC have no such feature. Progressive decoding in AVIF was added a few years back.
- Support for animation.
- Support for alpha transparency.
- Depth map support.
1 dicembre 2025
Il codice che decide l'esito della ruota della fortuna degli sconti Black Friday su efarma.com/spin:
const prizes = {
BF5: { label: "5% di sconto", code: "BF5", desc: "Senza minimo d'ordine" },
BF15: { label: "15% di sconto", code: "BF15", desc: "Ordine minimo 69,90€" },
BF25: { label: "25% di sconto", code: "BF25", desc: "Ordine minimo 129,90€" }
};
// ordine reale degli 8 spicchi partendo dall'alto (senso orario)
// 1: -15% 2: -25% 3: -5% 4: -15%
// 5: -25% 6: -5% 7: -15% 8: -5%
const segmentsPrizeKeys = [
"BF15", // 1
"BF25", // 2
"BF5", // 3
"BF15", // 4
"BF25", // 5
"BF5", // 6
"BF15", // 7
"BF5" // 8
];
// scegli uno spicchio 0–7
const segmentIndex = Math.floor(Math.random() * 8);
const prizeKey = segmentsPrizeKeys[segmentIndex];
const prize = prizes[prizeKey];
#189 /
13:27
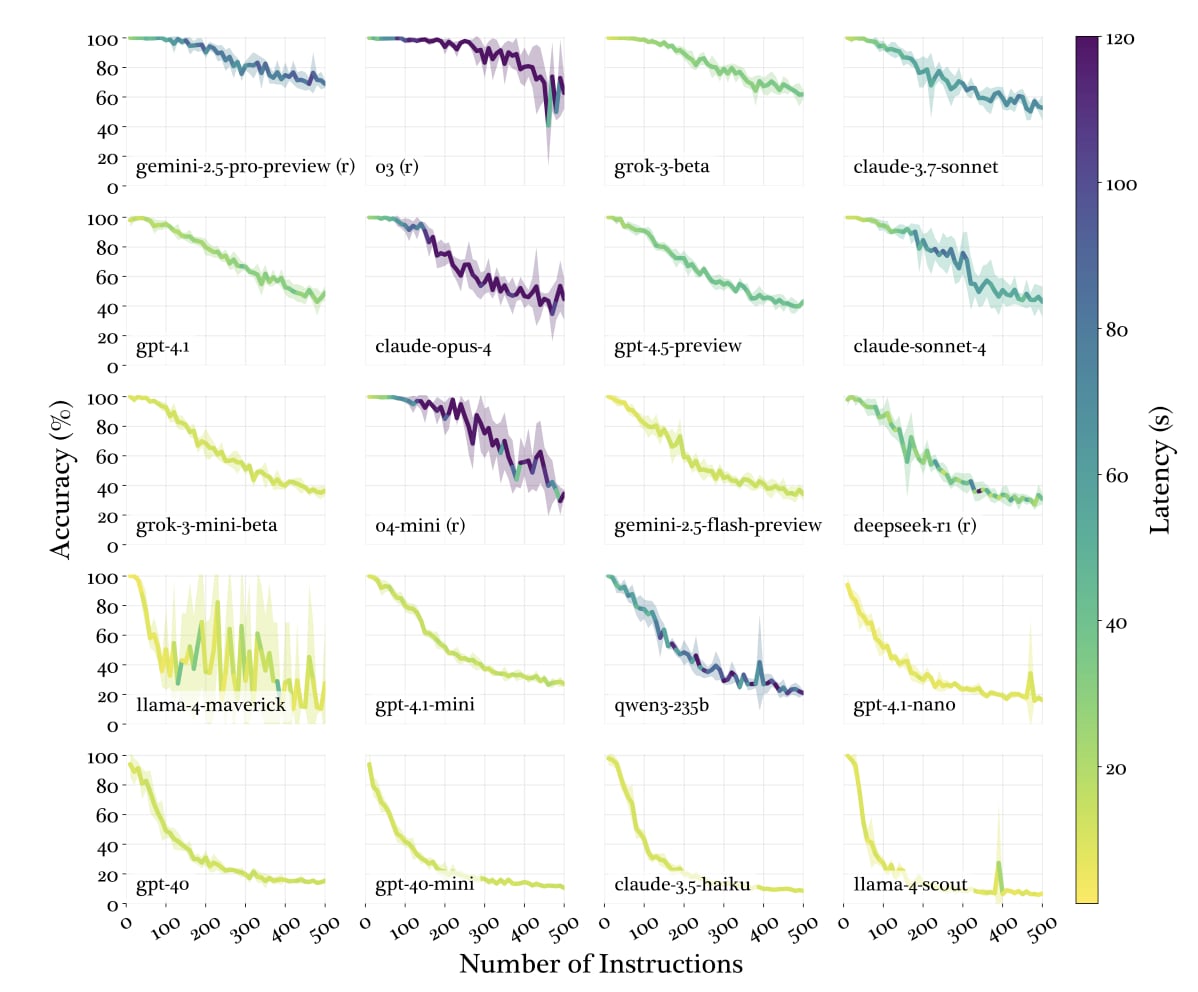
Quante istruzioni un LLM di frontiera è in grado di rispettare in un prompt? Non più di 150-200:
30 novembre 2025
TIL buona parte del Web 1.0 era ospitato da GeoCities, servizio chiuso nel 2019 ma in parte archiviato su GeoCities Gallery.
Ora c'è Neocities.org che ospita più di un milione di siti con la stessa filosofia.


Da The indie web is here to make the internet weird again:
The indie web is about reclaiming space on the internet for human-created content. It’s not about creating the best website, the most optimized one, or the most popular one. It’s about creating whatever you want without caring what an algorithm thinks of it or worrying about an AI ripping it off.
What stood out to me most, and surprised me the most, was how the indie web feels. [...] Rather than the cold apathy I feel while scrolling through Google or social media, I was genuinely curious what the next website would hold, what weird design it would feature, what funky music or fun facts it would include. Some personal websites contained journal entries that left me feeling like I was actually getting to know the person who wrote them, a distinct change from the snarky Twitter posts and tag-filled Instagram captions I’ve grown used to.
Interessante il postmortem di Incident.io per l'outage AWS di ottobre in us-east-1:
We’re hosted in multiple regions of Google Cloud and so the majority of our product was unaffected by the outage. However, we do depend on third parties for some aspects of our platform, who themselves are hosted in AWS, or have their own dependencies that are.
Il paradosso è che Incident.io serve proprio nelle occasioni in cui ci sono outage, e molte feature avevano problemi, incluso il sistema di autenticazione, il bot di trascrizione dei meeting, le notifiche via SMS e le chiamate, ma soprattutto l'impossibilità di fare deployment di codice perché Docker Hub era offline.
We use Google Container Registry to host our built docker images, which wasn’t impacted by the AWS outage at all, so we were surprised to see failures. We quickly realised however, that the issue actually lay with our base image (
golang-1.24.9-alpine). Crucially, this resolved to a Docker registry image, and Docker runs their registry on AWS.
I tentativi di aggirare il problema non sono andati a buon fine e non c'erano nell'immediato alternative che non avessero una dipendenza su AWS.
Differentemente il servizio Ably (API realtime) aveva un sistema multi-region che è funzionato correttamente:
During this week’s AWS us-east-1 outage, Ably maintained full service continuity with no customer impact. This was our multi-region architecture working exactly as designed; error rates were negligibly low and unchanged throughout.
E la Svizzera invece ha ora una posizione ufficiale sull'evitare i servizi cloud USA all'interno delle autorità statali:
The Conference of Swiss Data Protection Officers, Privatim, has severely restricted the usability of international cloud services – particularly hyperscalers like AWS, Google, or Microsoft – for federal authorities in a resolution. At its core, the resolution from Monday amounts to a de facto ban on the use of these services as comprehensive Software-as-a-Service (SaaS) solutions whenever particularly sensitive or legally confidential personal data is involved. For the most part, authorities will likely only be able to use applications like the widespread Microsoft 365 as online storage.
Questione da tenere d'occhio: una sentenza in Canada chiede a OVHcloud di fornire dati sotto il controllo della parent company globale di OVH, con sede in Francia. Fornire quei dati sarebbe illegale per la legge francese, ma se OVH non si rende conforme alla sentenza starebbe violando la legge canadese. Dove è presente con un'entità locale indipendente per i servizi cloud.
29 novembre 2025
A volte Codex CLI è veramente stupido:
I need to inspect each file that imports '$lib/app/responses/domains-groups', but I failed due to quoting the route path incorrectly. I haven’t modified anything yet.
E si ferma.
28 novembre 2025
Ennesima prova che la città 30 funziona. Dati di Bologna nel primo anno (2024):
- -13% incidenti
- -50% morti
- -11% feriti
- -30% feriti in codice rosso
- -13% flussi veicolari
- +10% flussi di biciclette
- +30% uso urbano del sistema ferroviario
- il tempo di viaggio medio in auto aumenta in quantità irrilevante, da 16 minuti a 16 minuti e 54 secondi
- nessun aumento dell'inquinamento atmosferico, NO2 -31%
- limite rispettato nel 60% dei casi a un anno dall'inizio, in linea con Amsterdam
- nessuna variazione nei tempi di percorrenza delle ambulanze
25 novembre 2025
Assurdi i numeri del blocco spoofing mobile:
Un altro operatore ha fornito anche il totale delle chiamate. Dal 19 al 23 novembre, su un totale di 17 milioni, 8,3 milioni sono state chiamate spoofing annullate dal filtro. 1,7 milioni al giorno. Circa il 50%. [...]
Per una telco ci sono solo i dati del 21 novembre, e sono impressionanti. Su circa 3,15 milioni di chiamate mobili, 2,9 milioni sono state bloccate, ovverosia circa il 90% delle chiamate ricevute.
Un altro gestore, tra il 20 e il 23, ha bloccato circa 650.000 chiamate su un totale di circa 940.000 chiamate da mobile. Anche qui siamo su una percentuale molto alta, circa il 70%.
(DDay)
#181 /
17:23
Archivio
- 2026
- giugno (29)
- maggio (29)
- aprile (67)
- marzo (55)
- febbraio (40)
- gennaio (54)
- 2025
- dicembre (79)
- novembre (63)
- ottobre (102)
- settembre (22)
Tag
- #ai (113)
- #cloud (55)
- #dev (48)
- #italia (47)
- #digitalizzazione (26)
- #business (26)
- #openai (25)
- #security (22)
- #internet (22)
- #cdn (21)
- #mondo (21)
- #database (19)
- #social (18)
- #reti (18)
- #cloudflare (17)
- #aws (16)
- #google (15)
- #informazione (15)
- #video (15)
- #claude (15)
- #browser (14)
- #mobilità (13)
- #storage (13)
- #macos (12)
- #anthropic (11)
- #domini (11)
- #meta (10)
- #github (10)
- #scrivere (10)
- #dns (8)
- #web-dev (8)
- #open-source (7)
- #design (7)
- #pagopa (7)
- #telegram (7)
- #http (7)
- #email (6)
- #git (6)
- #codex (6)
- #dataviz (6)
- #tlc (6)
- #amazon (6)
- #hetzner (5)
- #bending-spoons (5)
- #libri (5)
- #privacy (5)
- #ovh (5)
- #microsoft (5)
- #antipirateria (4)
- #agenziadelleentrate (4)
- #innovazione (4)
- #streaming (4)
- #waymo (3)
- #mistral (3)
- #kubernetes (3)
- #whatsapp (3)
- #energia (3)
- #cie (3)
- #ipv6 (3)
- #apple (3)
- #opendata (3)
- #colori (2)
- #eu (2)
- #windows (2)
- #datacenter (2)
- #android (2)
- #javascript (2)
- #trenitalia (2)
- #broadcasting (1)
- #markdown (1)
- #blog (1)
- #postgres (1)
- #dotnet (1)
- #revolut (1)
- #rai (1)
- #akamai (1)
- #legal (1)
- #redis (1)
- #tailscale (1)