Nel 2026 uscirà Video.js 10, nuova versione dell'ultrapopolare player video JavaScript. Sarà essenzialmente riprogettato fondendo concetti di Plyr, Media Chrome e Vidstack per renderlo compatibile con lo sviluppo moderno a componenti/React.
25 novembre 2025
24 novembre 2025
Hit a new daily peak, serving over 20M HTTP requests per second straight from our CDN77 network.
20M. Every second.
Wild. And our Logs team (data & storage eng): "Ok, nice benchmark, give us more". Respect!
We store logs with 1+2 redundancy.
That is 60 000 000 lines per second. The fun's only beginning.
It’s human nature to provoke especially if it has no consequences. On X being a provocateur comes with financial reward. So of course civility breaks down and discourse becomes increasingly toxic because you make money with little to no social consequences.
You can either have constructive, civil discourse with context of identity, be rewarded for putting your neck on the line or preserve your privacy & anonymity, continue to be a provocateur but with nothing to gain from it.
You just have to stop incentivizing anonymous posting with $$$.
I'm sure some of these are state/political projects, but I suspect most are just smart people in low and middle income countries doing it for the money, because Twitter invented a direct and quick way to make cold hard cash from making Americans angry and upset online.
Mike Bird (The Economist)
22 novembre 2025
TIL una build di Chromium richiede 3-4 giorni in locale.
Rebuilds are notoriously slow. A full Chromium build can take 3-4 days on standard development hardware like a MacBook laptop, assuming nothing fails. Every modification means another full rebuild to validate changes, and iterating on patches under those conditions quickly turns into multi-week cycles.
19 novembre 2025
Molti dei prodotti delle “intelligenze artificiali” di cui parliamo quotidianamente mi sembra siano finora prodotti già esistenti, che queste tecnologie ci stanno aiutando a ottenere con minor impegno e a volte con maggiore qualità di quelli che avremmo ottenuto senza quelle tecnologie (tutte le immagini che vediamo prodotte da “intelligenze artificiali” possono essere realizzate con Photoshop; dei testi celebriamo proprio quanto siano simili a quelli umani, non diversi, impensati o eccezionali; eccetera). Non vedo – in questa gran parte di esempi protagonisti delle esperienze e conversazioni quotidiane della maggioranza delle persone – produzioni di cose o funzioni nuove e prima inesistenti, né effetti nuovi di quelle produzioni che trasformino le vite degli umani (salvo che nel tempo che liberano, o nel lavoro che sottraggono). In gran parte parliamo di “contenuti”: testi, immagini, suggerimenti, insegnamenti. Insomma, al momento niente sembra paragonabile alle trasformazioni indotte nelle nostre vite, nelle nostre società, persino nelle nostre teste, dalle innovazioni degli scorsi decenni. Al momento.
Un giovane molto esperto e molto coinvolto nelle cose delle “intelligenze artificiali” mi ha messo le cose in una prospettiva interessante, pochi giorni fa: secondo lui esistono “intelligenze artificiali cattive” in quanto fanno cose al posto nostro atrofizzando in prospettiva la nostra capacità di farle e rincoglionendoci ancora di più (che le trasformazioni digitali degli scorsi decenni ci abbiano in parte rincoglionito è ormai dato per condiviso); ed esistono “intelligenze artificiali buone” che invece possiamo usare per migliorarle, le nostre capacità, e aumentare le nostre conoscenze e competenze. Mi è sembrata fin qui una lettura convincente: se ci pensate, è successo anche con la storia dell’umanità pre-digitale che i progressi tecnici e i nuovi strumenti ci sollevassero dal saper fare delle cose grazie al fatto che quelle cose le sapeva fare qualcun altro (parliamo di competenze e capacità, qui, non di rapporti di forza). E che nel frattempo i progressi civili e tecnici venissero sfruttati anche per aumentare altre conoscenze di tutti: attraverso la scuola, l’informazione giornalistica, la divulgazione, i libri, eccetera. La differenza adesso sarebbe che non avverrebbe più la seconda cosa, perché la conoscenza verrà tutta indirizzata verso i software (poi forse, dicono in molti, non ci sarà più conoscenza da indirizzare): la distribuzione di sapere tra gli umani si azzererà.
TIL PagoPA si è stufata di stare dietro ai bonus e ha fatto una piattaforma chiamata PARI per permettere alle varie pubbliche amministrazioni di distribuire bonus tramite l'app IO.
Dal postmortem di Cloudflare:
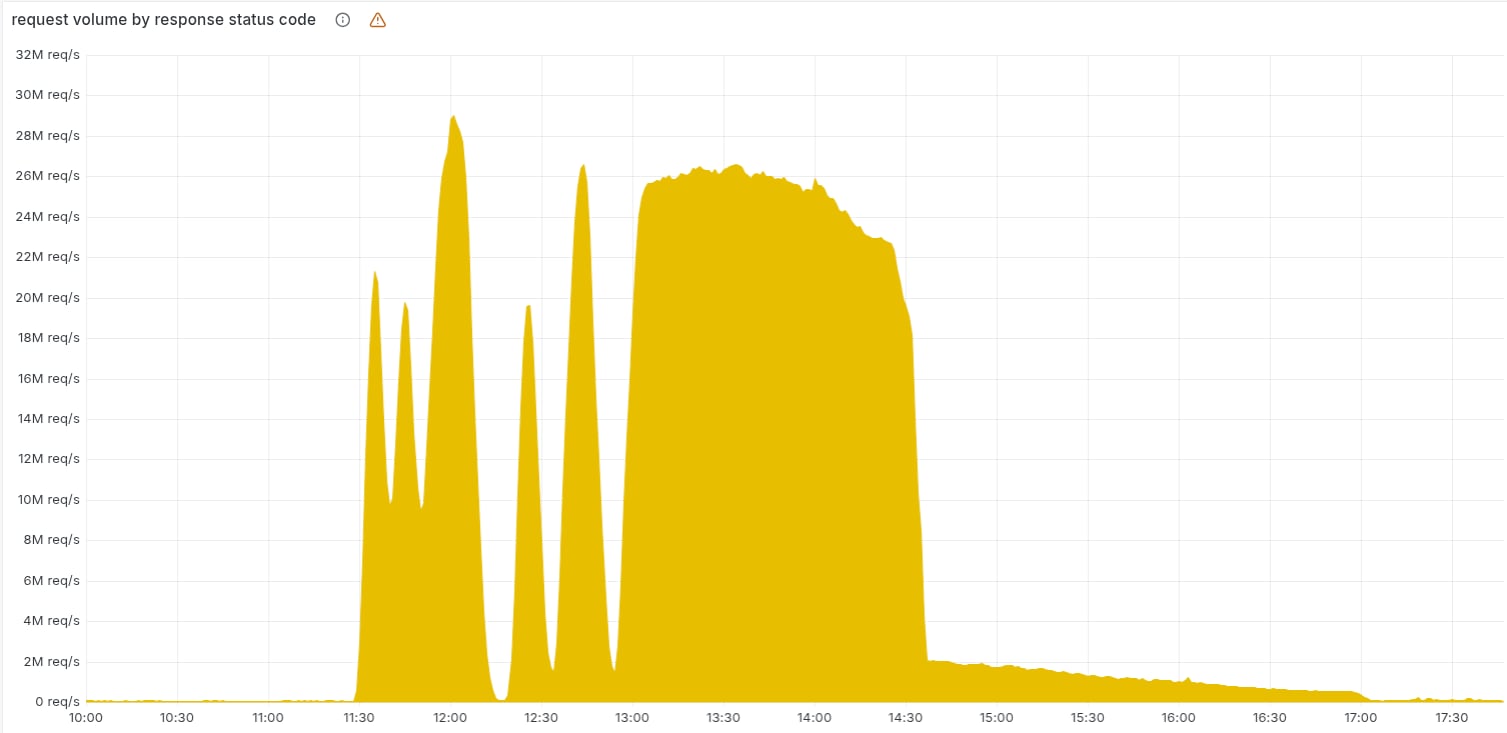
Il motivo delle fluttuazioni iniziali di errori 5xx è dovuto al deployment di un file di configurazione errato del "bot score" della Bot Protection:
As a result, every five minutes there was a chance of either a good or a bad set of configuration files being generated and rapidly propagated across the network.
E infine veniva sempre deployato il file errato, globalmente e istantaneamente (la stessa causa di altri precedenti outage globali di Cloudflare):
The model takes as input a “feature” configuration file. A feature, in this context, is an individual trait used by the machine learning model to make a prediction about whether the request was automated or not. The feature configuration file is a collection of individual features.
This feature file is refreshed every few minutes and published to our entire network and allows us to react to variations in traffic flows across the Internet. It allows us to react to new types of bots and new bot attacks. So it’s critical that it is rolled out frequently and rapidly as bad actors change their tactics quickly.
Il motivo per cui alcuni siti non erano affetti:
Customers deployed on the new FL2 proxy engine, observed HTTP 5xx errors. Customers on our old proxy engine, known as FL, did not see errors, but bot scores were not generated correctly, resulting in all traffic receiving a bot score of zero. Customers that had rules deployed to block bots would have seen large numbers of false positives.
Il file di configurazione conteneva dei dati errati perché per via di un cambio di configurazione la query ClickHouse estraeva più dati del dovuto. Il proxy edge lanciava un'eccezione perché non si aspettava quella quantità di dati:

Cosa c'era quindi che non andava:
- La query era errata (ok, può capitare).
- Non c'era validazione dell'output della query (feature duplicate), che finiva quindi direttamente deployato globalmente, a quanto pare.
- Sull'edge c'era un limite fisso di 200 feature attese, ma non c'era nessuna validazione che il file ne avesse effettivamente di meno.
- Non c'era nemmeno "fail safe" nel caso in cui succedesse.
EDIT: su Hacker News osservazioni molto simili:
They failed on so many levels here.
How can you write the proxy without handling the config containing more than the maximum features limit you set yourself?
How can the database export query not have a limit set if there is a hard limit on number of features?
Why do they do non-critical changes in production before testing in a stage environment?
Why did they think this was a cyberattack and only after two hours realize it was the config file?
Why are they that afraid of a botnet? Does not leave me confident that they will handle the next Aisuru attack.
Anche Resend durante l'outage Cloudflare ha iniziato a lavorare per sostituire Cloudflare con AWS CloudFront, ma alla fine non l'ha fatto e preferisce avere l'edge AWS (dove c'è il resto dell'infrastruttura) solo come failover.
The CloudFront solution was not deployed, but the runbook was created. If the incident were to recur, we could switch to the fallback within 60 seconds. We continued to monitor and then closed the status page.
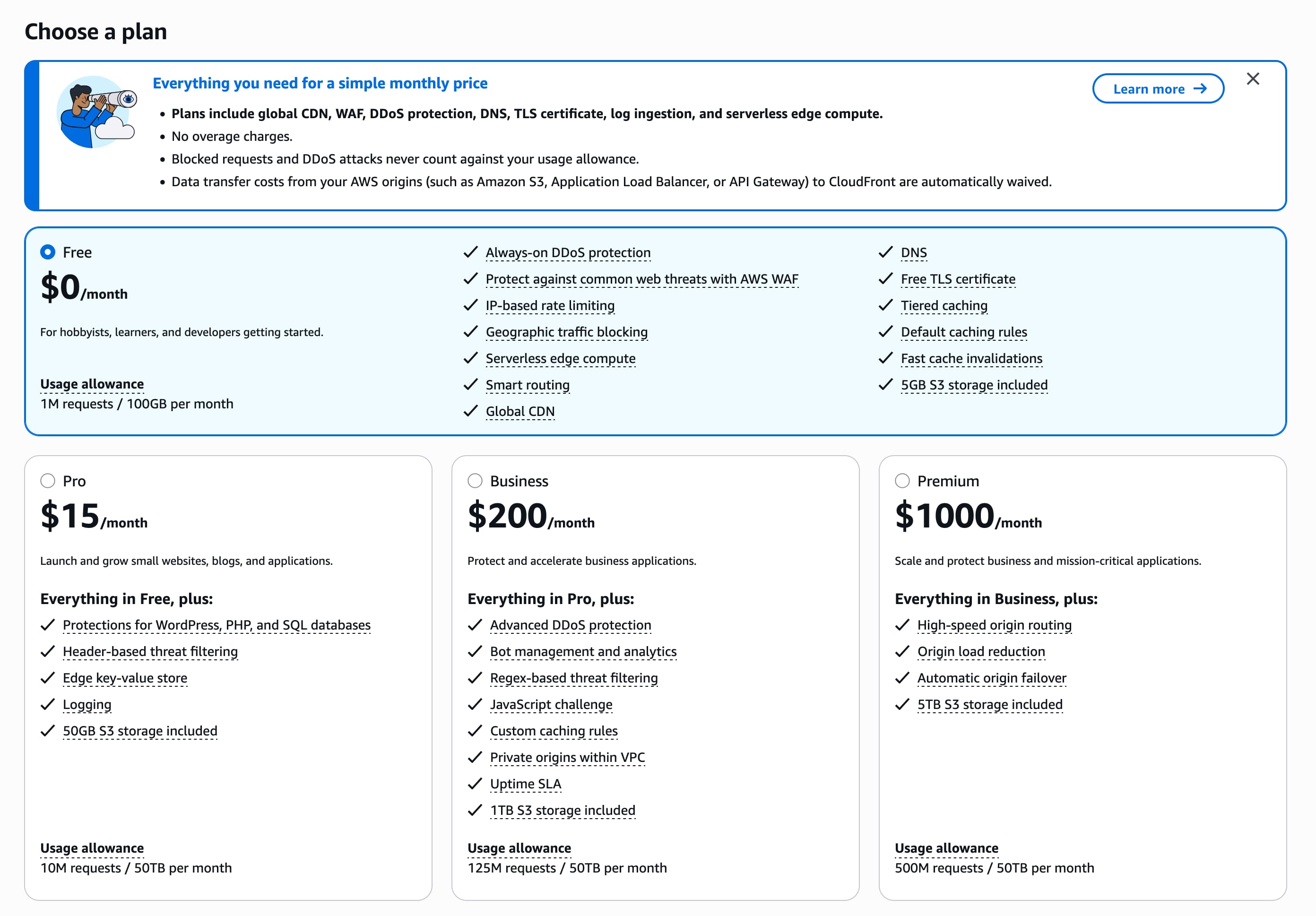
Rivoluzione dei prezzi di AWS CloudFront, 50 TB per 15$ (in su), prima sarebbe costato oltre 4.000 $:
18 novembre 2025
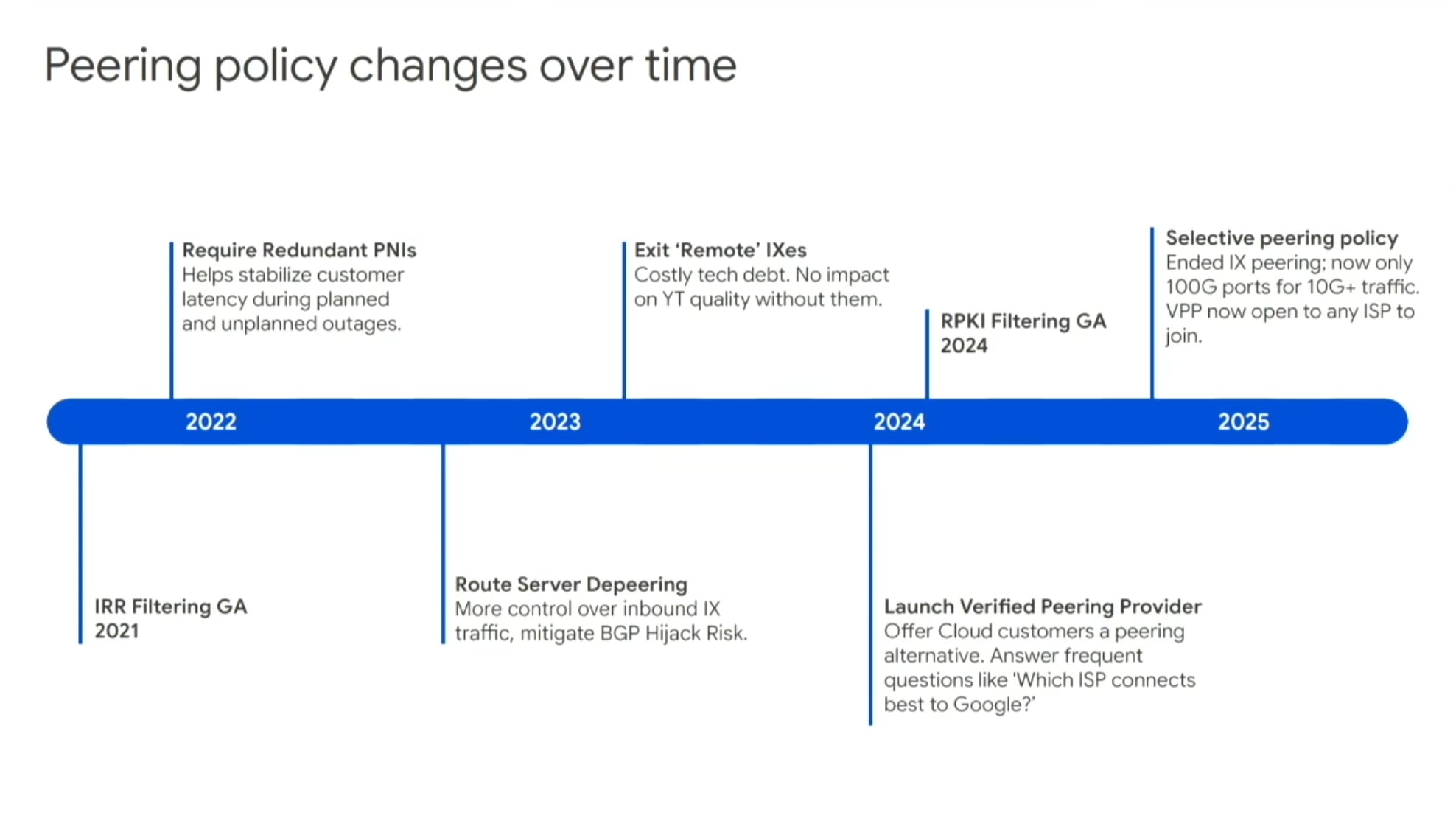
Di recente Google ha cambiato la policy di peering per quanto riguarda Google Cloud e YouTube:
- Niente più nuovi peering negli IXP pubblici.
- PNI min. 100 Gbps su traffico minimo di 10 Gbps di picco (settlement free).
- Per tutto il resto il consiglio è di affidarsi a uno degli ISP "certificati" di questa lista (IP transit a pagamento, presumo), che hanno almeno due interconnessioni in almeno un'area metropolitana di Google.
(video)
Private peering allows a network to connect directly with Google over a dedicated physical link known as a private network interconnect (PNI).
Google offers 100G and 400G private peering (PNI) at the facilities listed in our PeeringDB entry. Note that this type of direct peering occurs at common physical locations, and both Google and any peering network bear their own costs in reaching any such location.
Google no longer accepts new peering requests at internet exchanges (IXPs). However, Google maintains dedicated connectivity to the internet exchanges (IXPs) listed in our PeeringDB entry. We also maintain existing BGP sessions across internet exchanges where we are connected. For networks who do not meet our PNI requirements Google will serve those networks via indirect paths.
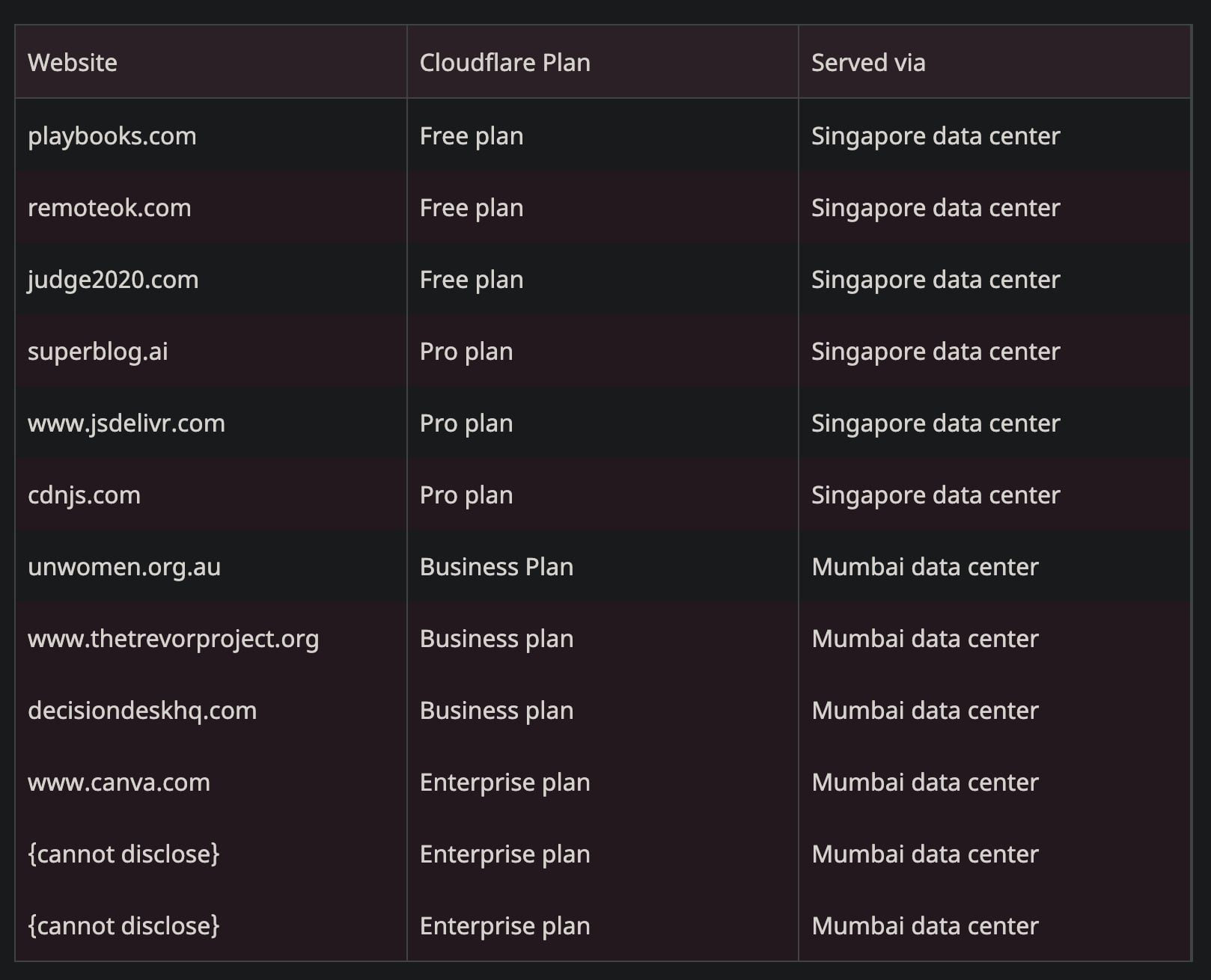
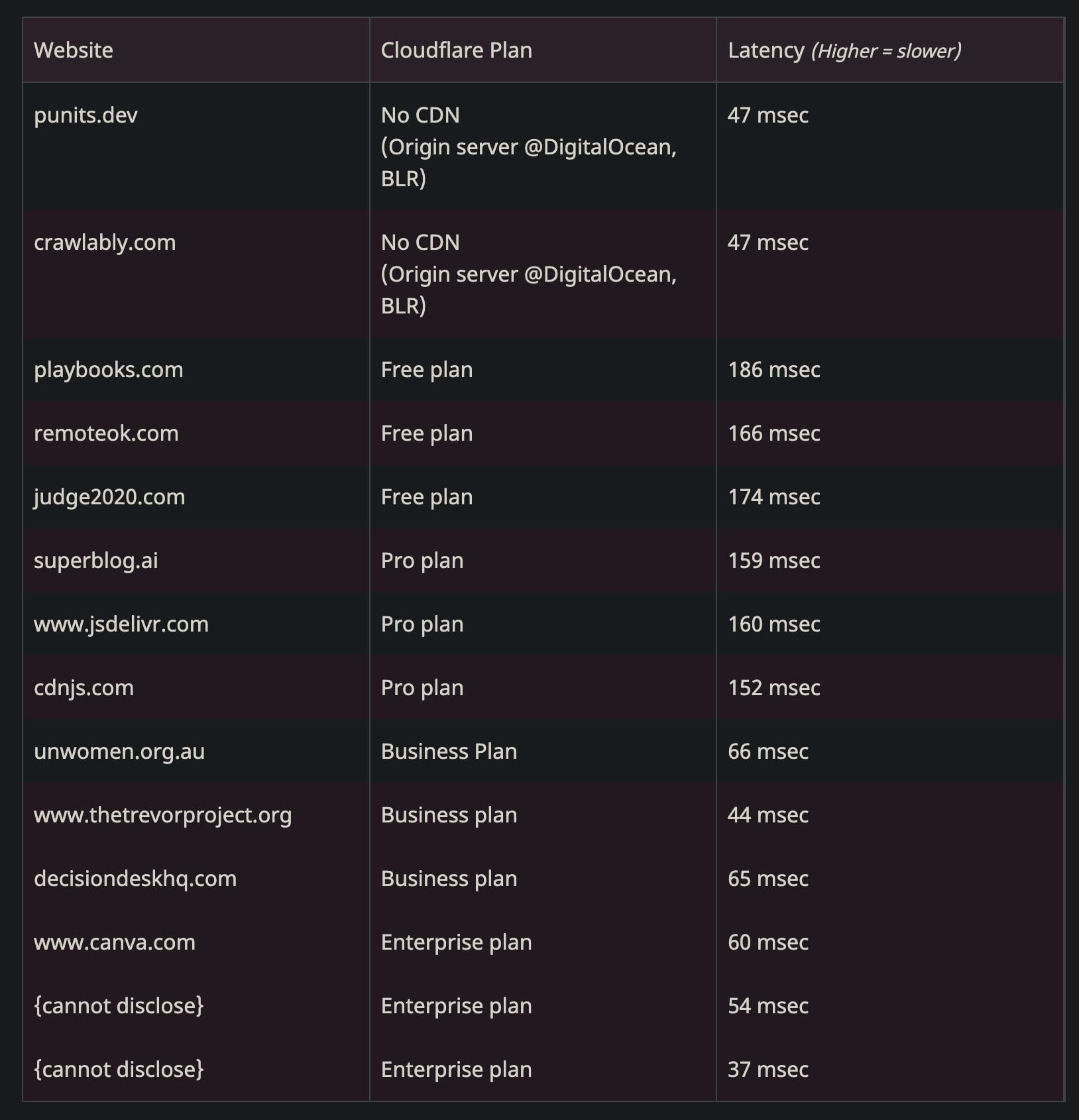
Altra testimonianza di come il routing Cloudflare sia pessimo sui piani più economici (producendo 150+ ms di latenza evitabile scegliendo nodi a migliaia di km di distanza), un problema che essenzialmente non esiste con le altre CDN:
In my experience, the people who are excited about AI art also happen to be some of the most talentless fucking people I've ever met. They're middle managers, executives, or marketers whose LinkedIn bio reads: "I'm the Chief Brand Officer of User Engagement at DataRectal, but what I really am is a storyteller".
AI art is an interesting technology because despite its growing popularity, nobody seems to want it.
Matthew Inman, fumettista, in un fumetto sulle immagini/video generati con AI.
TIL OONI.org (Open Observatory of Network Interference) è una global community measuring Internet censorship since 2012. Si installa la probe e si eseguono test che sono poi esplorabili e finiscono nei report sulla censura.
A dimostrazione di #164, ho notato che diversi siti hanno disattivato Cloudflare visto il prolungarsi dei problemi: Mailtrap, Instatus, X. E allora cosa era lì a fare?
Cloudflare KO da quasi due ore e la differenza rispetto a quando us-east-1 di AWS è down è che i disservizi Cloudflare tendono ad essere globali e quindi più impattanti.
La quantità di siti impattati che sto osservando mi sembra maggiore rispetto all'outage AWS del mese scorso. A questo giro noto cloud provider con i siti in crisi (Netsons), servizi di status page (Instatus), di rilevamento errori (Bugsnag), di invio email (Mailtrap, Resend) che usano Cloudflare magari senza nemmeno averne bisogno, magari perché "lo usano tutti", "costa poco", e senza un'adeguata valutazione di cosa comporta far passare l'intero traffico non cifrato attraverso un'azienda che non ha una reputazione di affidabilità. A questo giro anche ChatGPT, X e N26.
Magari anche con l'illusione che Cloudflare serva a qualcosa out of the box nel gestire gli attacchi DDoS. Non lo è: gli attacchi L3/L4 li gestisce tipicamente ogni provider di rilievo (almeno fino a una certa scala) e non è per questo necessario Cloudflare, mentre è noto a chi ci è passato che Cloudflare ha l'abitudine di passare alla origin gli attacchi L7 anche significativi (decine di migliaia di richieste al secondo), fuori pattern e con origin palesemente in crisi. Di certo è un utile, flessibile e soprattutto accessibile firewall edge a scalabilità infinita che avrebbe bisogno di più competizione.
La region OVHcloud di Milano con 3 AZ è live.
17 novembre 2025
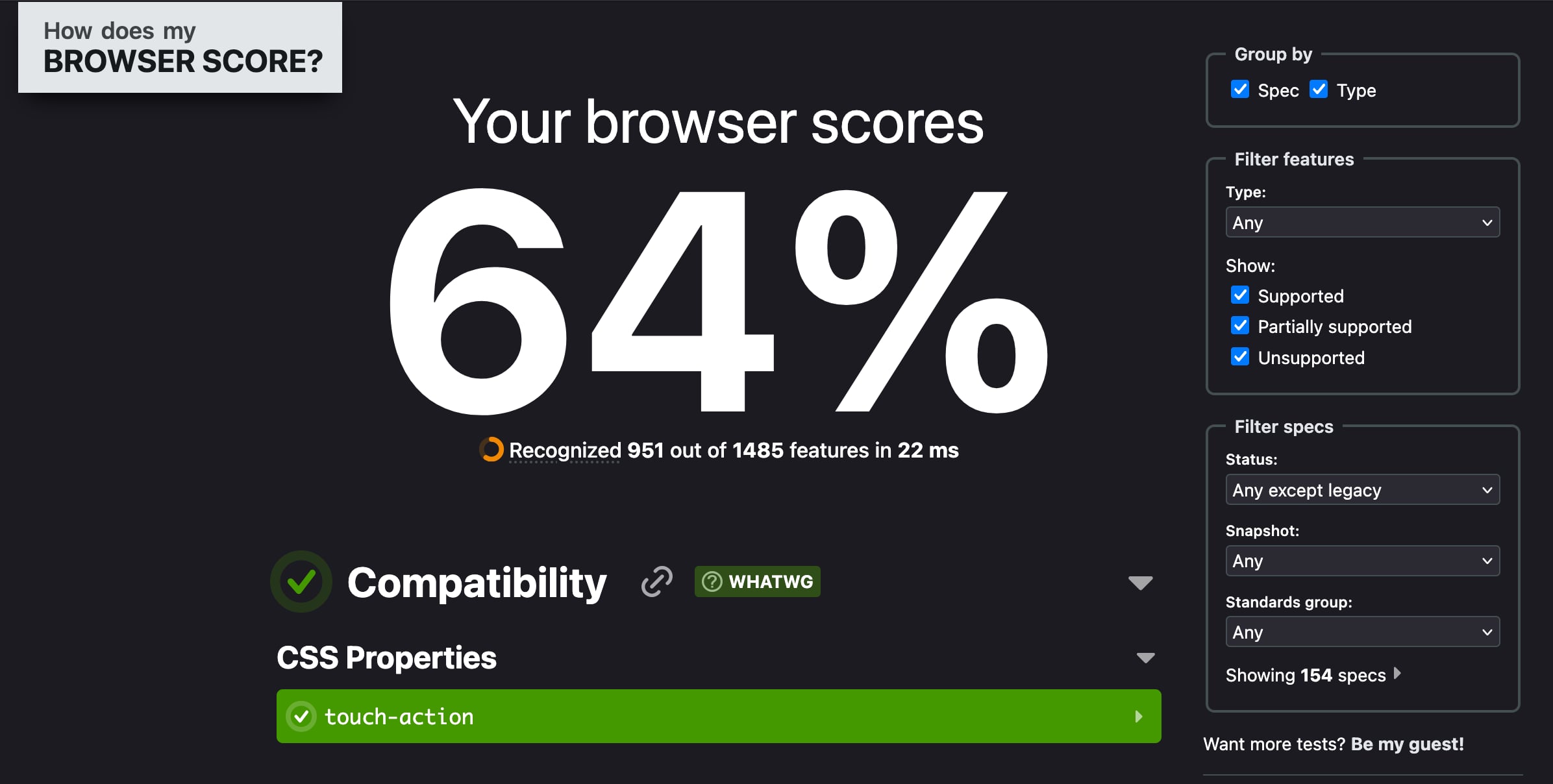
Browser Score permette di verificare se il proprio browser supporta determinate feature di CSS.
Review your own git pull requests
When you create a pull request in GitHub, click on the Files changed tab, and scroll through the diff. Anywhere you’ve done something new that’s not already explained by in-code comments, add a comment in the GUI about what you did and why.
- Often, it’s stuff that’s not important enough for in-code commentary, but is useful for the reviewer to know.
- Sometimes, it’s stuff that should actually be documented in the code, and this is a good time to go back and add it.
- Every now and then, you’ll notice a bug in your own code because you’re reading it with fresh eyes, in a different format than your text editor.
It’s a simple behavior change that adds maybe 5 or 10 minutes to the time it takes to setup a PR, but it’s saved me so many headaches, and makes life for whoever reviews your PR a lot easier, too!
Archivio
- 2026
- giugno (29)
- maggio (29)
- aprile (67)
- marzo (55)
- febbraio (40)
- gennaio (54)
- 2025
- dicembre (79)
- novembre (63)
- ottobre (102)
- settembre (22)
Tag
- #ai (113)
- #cloud (55)
- #dev (48)
- #italia (47)
- #digitalizzazione (26)
- #business (26)
- #openai (25)
- #security (22)
- #internet (22)
- #cdn (21)
- #mondo (21)
- #database (19)
- #social (18)
- #reti (18)
- #cloudflare (17)
- #aws (16)
- #google (15)
- #informazione (15)
- #video (15)
- #claude (15)
- #browser (14)
- #mobilità (13)
- #storage (13)
- #macos (12)
- #anthropic (11)
- #domini (11)
- #meta (10)
- #github (10)
- #scrivere (10)
- #dns (8)
- #web-dev (8)
- #open-source (7)
- #design (7)
- #pagopa (7)
- #telegram (7)
- #http (7)
- #email (6)
- #git (6)
- #codex (6)
- #dataviz (6)
- #tlc (6)
- #amazon (6)
- #hetzner (5)
- #bending-spoons (5)
- #libri (5)
- #privacy (5)
- #ovh (5)
- #microsoft (5)
- #antipirateria (4)
- #agenziadelleentrate (4)
- #innovazione (4)
- #streaming (4)
- #waymo (3)
- #mistral (3)
- #kubernetes (3)
- #whatsapp (3)
- #energia (3)
- #cie (3)
- #ipv6 (3)
- #apple (3)
- #opendata (3)
- #colori (2)
- #eu (2)
- #windows (2)
- #datacenter (2)
- #android (2)
- #javascript (2)
- #trenitalia (2)
- #broadcasting (1)
- #markdown (1)
- #blog (1)
- #postgres (1)
- #dotnet (1)
- #revolut (1)
- #rai (1)
- #akamai (1)
- #legal (1)
- #redis (1)
- #tailscale (1)